렘은 언제나 성능을 최적화할 여러 방법을 찾고 있습니다. 이 글은 C++ STL에 비해 24% 향상된 수행 시간을 가진 이진탐색 트리를 개발한 과정을 다룹니다.
왜 이진 탐색인가?
렘은 데이터를 이진 트리 구조에 저장합니다. 예를들어 렘이 연결 리스트의 다음의 ID들을 가지고 있다고 가정해봅시다.

만약 ID가 14인 객체를 찾기 원한다면 5번의 연산, O(n) 복잡도가 필요합니다.
속도를 올리는 방법 중 하나는 이진 탐색을 사용하는 것입니다.
“이진 탐색 알고리즘은 정렬된 배열의 가운데 요소의 값과 목표 값을 비교하는 것에서 시작한다. 만약 목표 값이 작다면, 검색은 작은 값을 가진 절반의 배열에서 검색을 계속한다. 이 작업은 해당 요소를 찾을 때나 더 이상 배열에서 찾을 요소가 없을 때까지 반복된다. 해당 요소를 찾으면 위치를 반환하고 찾지 못했다면 “찾지 못함”을 의미하는 표식을 반환한다.” -위키피디아
객체들을 연결 리스트에 넣는 대신 이진 트리에 보관할 수 있습니다. 이 구조는 루트 노드부터 트리를 탐색하는 이진 탐색를 통해 객체를 식별할 수 있게 힙니다. 이진 트리의 ID들은 이와 같은 모습입니다.
14와 같은 ID의 객체를 찾는 것은 이제 3번의 연산, O(log2(N)) 복잡도가 됩니다.
이것을 보았을 때, 렘은 이진 탐색이 꽤 최적화 해볼만한 대상이라고 생각했습니다.
C++ 표준 라이브러리 (STL)에는 std::lower_bound(), std::upper_bound() 등의 여러 이진 탐색 함수가 있습니다. 우리는 std::upper_bound()의 동작을 흉내내고 이를 유닛 테스트에서 참조 대상으로 사용하기로 하였습니다. 이 함수는 주어진 값보다 큰 첫째 요소 위치를 찾는 이진 탐색 버전입니다.
// For a sorted list, vec, return the index of the first element that compares
// greater to the value, or return vec.size() if no such element is found.
size_t match = std::upper_bound(vec.begin(), vec.end(), value) - vec.begin();
위와 같은 ID들을 사용하고 13을 std::upper_bound()에 적용하는 예를 들어보겠습니다. 이는 4를 반환하는데, 13보다 큰 첫번째 요소가 14기 때문입니다.

테스트 설정
추후에 아키텍쳐를 추가할 계획 이지만 현재 Realm은 모바일 디바이스에서의 성능개선을 목표로하고 있습니다. 그래서, 벤치마크에는 아래 단말을 선택했습니다.


Top: Huawei P7 phone with a 32-bit Huawei Kiri 910T (ARMv7 / Cortex-A9)
Bottom: HP Envy dv6 laptop with a 64-bit Intel Core i7-3630QM
현재 iOS 용으로는 clang++ 컴파일러를, 안드로이드와 리눅스에는 g++, 윈도에서는 비주얼 스튜디오를 사용하고 있기 때문에, 아래와 같이 설정을 하였습니다.

우리는 ARM에서 Thumb 모드를 사용하지 않는데, 저희가 사용하는 일부 코드에서 ARM 모드의 절반 정도 밖에 성능이 안 나오기 때문 입니다. (주: Thumb는 ARM의 모드로 간결한 명령어들을 사용하는 모드로 리소스가 부족한 장비에서 주로 사용됩니다.)
기준
먼저 std::upper_bound() 자체를 비교의 기준으로 삼아 살펴보겠습니다. 우리는 모든 곳에 size_t(앞으로 T라고 표기) 형을 사용합니다. 이 타입이 (32 혹은 64 비트) 프로세서의 원 레지스터 크기와 일치하기 때문입니다.
목록의 크기는 8192 요소로 정했습니다. ARM에서는 32 킬로바이트가 되고 L1 데이터 캐시 크기와 일치하게 됩니다. x64에서는 캐쉬의 두배 크기인 64 킬로바이트를 차지하기 때문에 L1 미스가 더 자주 발생한다. 그런 이유로 이 글이 ARM과 x64의 성능 비교는 아닙니다.
반복자(iterator) 대신 size_t를 반환하는 래퍼 std::upper_bound()를 만듭니다.
template <class T> INLINE size_t fast_upper_bound0(const vector<T>& vec, T value)
{
return std::upper_bound(vec.begin(), vec.end(), value) - vec.begin();
}
표준 C++ 라이브러리(libstdc++)에서 헤더 파일 stl_algo.h을 찾아 upper_bound() 안의 반복문을 살펴보겠습니다.
while (__len > 0)
{
_DistanceType __half = __len >> 1;
_ForwardIterator __middle = __first;
std::advance(__middle, __half);
if (__val < *__middle)
__len = __half;
else
{
__first = __middle;
++__first;
__len = __len - __half - 1;
}
}
return __first;
그리고 성능을 보면,

버전 1
STL 버전을 보면 if 문을 위한 두 경우 블록이 있습니다. 첫번째 블록은 대입문만 가집니다.
__len = __half;
그리고 두번째 블록은 3개의 문장을 가집니다.
__first = __middle;
++__first;
__len = __len - __half - 1;
2개의 문장과 1개의 문장만을 대신 반복하는 것로 첫번째 최적화를 시도해 보겠습니다.
template <class T> INLINE size_t fast_upper_bound1(const vector<T>& vec, T value)
{
size_t size = vec.size();
size_t i = 0;
size_t size_2 = size;
while (size_2 > 0) {
size_t half = size_2 / 2;
size_t mid = i + half;
T probe = vec[mid];
if (value >= probe) {
i = mid + 1;
size_2 -= half + 1;
}
else {
size_2 = half;
}
}
return i;
}
아래 어셈블리 코드에서 보이는 것 처럼 컴파일러는 우리가 지원하는 플랫폼 모두에서 단순한 1 대 1 번역을 생성했습니다. 각 경우마다 하나의 코드 블록과 어떤 블록이 수행될지 제어하는 분기 명령을 가집니다.
즉 컴파일러가 알고리즘을 바꾸지는 않는다는 것을 의미 하고, 따라서 성능은 STL코드에서 별로 나아지지 않았습니다. ARM 용 g++ 4.9.1이 루프를 일부 풀어버렸고 별도로 떨어져 있는 곳에서 분기에서 타고 갈 코드 블록에 두번째 if 케이스를 위치시킨 것을 볼 수 있습니다.
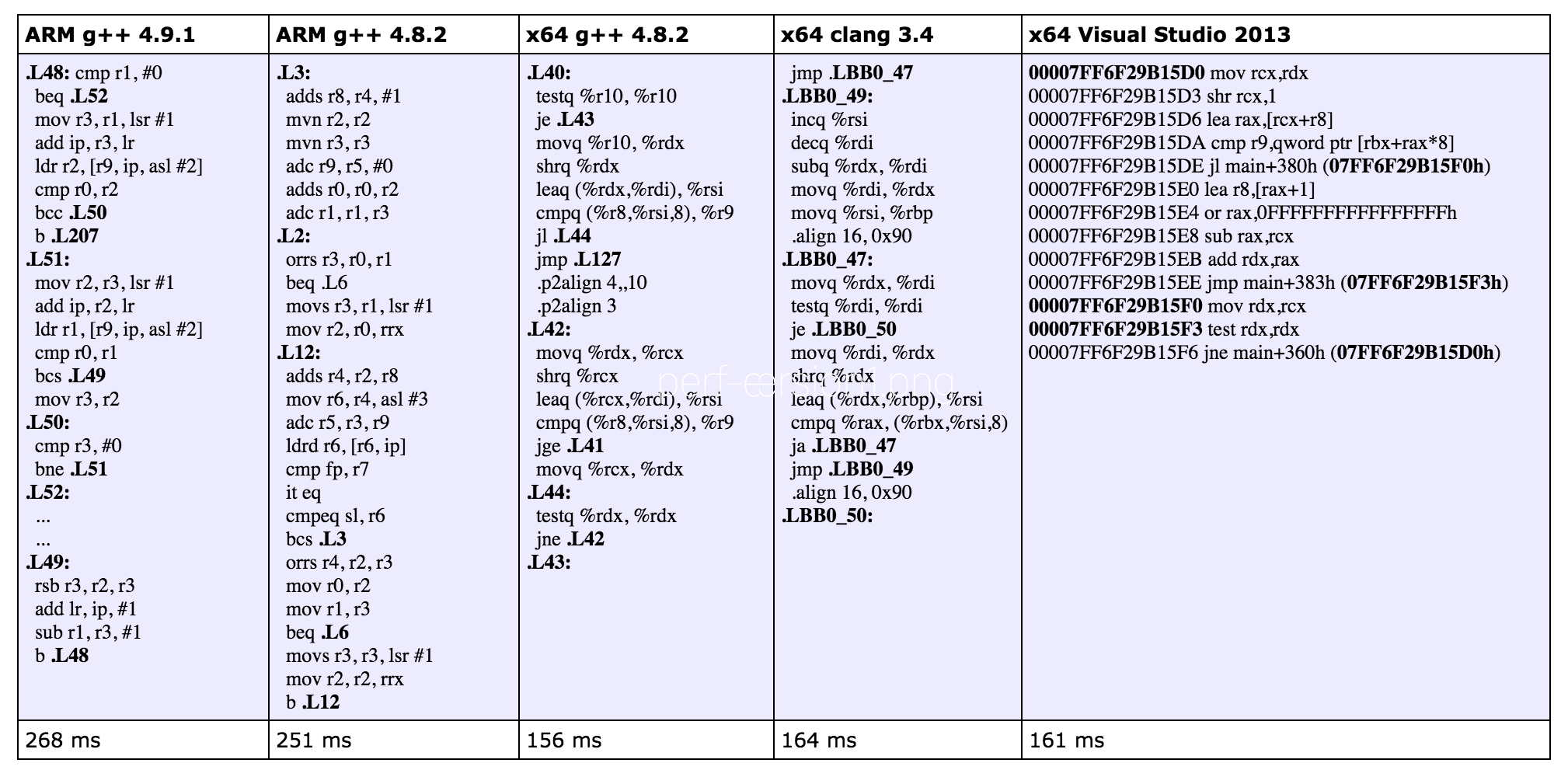
버전 2
이제는 알고리즘의 단순화를 시도합니다. 각 if 문은 두 케이스를 가지는 것은 동일하지만 이번에는 각 블록마다 한 줄의 대입문만 포함하고 두 대입문은 같은 소스 변수를 가지도록 합니다:
template <class T> INLINE size_t fast_upper_bound2(const vector<T>& vec, T value)
{
size_t m_len = vec.size();
size_t low = -1;
size_t high = m_len;
assert(m_len < std::numeric_limits<size_t>::max() / 2);
while (high - low > 1) {
size_t probe = (low + high) / 2;
T v = vec[probe];
if (v > value)
high = probe;
else
low = probe;
}
if (high == m_len)
return m_len;
else
return high;
}
g++과 clang에서는 조건문의 분기문을 조건 무브(conditional move)로 변환하여 의미있는 성능 향상을 보여주는데요, 하지만 비주얼 스튜디오에서는 그런 변환이 없어서 성능 향상이 없습니다.
(주: ARM은 다양한 조건 명령 (condition execution)을 가진다. 예를 들어 MOVEQ는 두 값이 동일할 때만 MOV가 되고 MOVNE은 두 값이 다를 때만 MOV가 실행이 된다. 이런 조건 명령은 분기 실패보다는 상대적으로 낫다. x64의 경우에는 mov 등의 제한된 명령이 조건 명령으로 제공된다.)
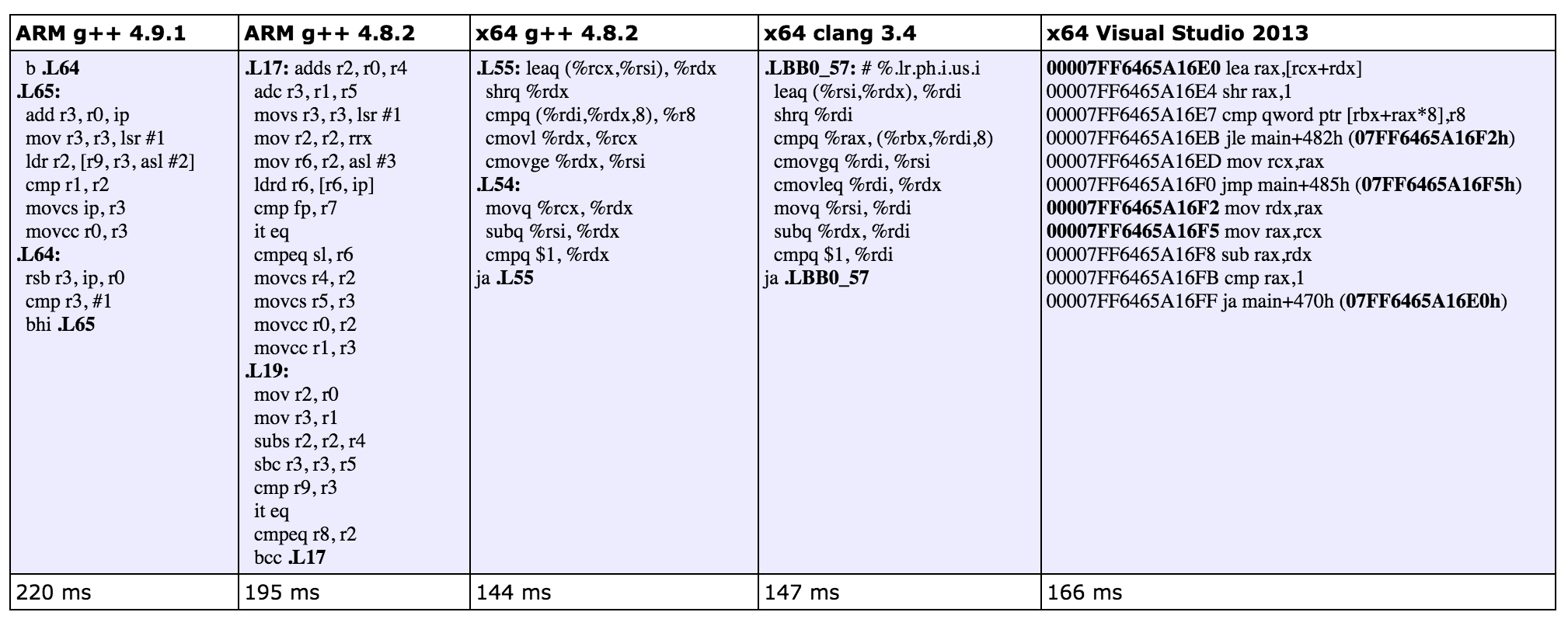
조건 분기와 조건 무브 중 어느 것을 사용해야 하는지는 반복문의 매 분기를 CPU가 정확히 예측할 수 있느냐 아니냐에 따라 결정할 수 있습니다.
조건이 대부분 참이거나, 아니면 거의 대부분 거짓이거나, 혹은 예측 가능한 패턴을 가지고 있다고 가정해 보겠습니다.
[true, false, true, false, true, false]
CPU의 분기 예측기는 대부분의 경우 분기를 정확히 예측 할 수 있다. 이 경우 분기는 매우 저렴해서 분기 무브와 속도로 견줄 수 있습니다.
이 메서드는 마이크로아키텍쳐에 따라, 또 상황에 따라 더 빠르게 동작합니다. CPU는 분기 무브에 대해서는 예측 로직을 가지지 못하기 때문에 어떤 마이크로아키텍쳐는 필요하지 않은 오퍼랜드(operand)의 경우에도 비싼 메모리로 부터 오퍼랜드를 가져오는 선택을 할 수 있습니다. 성능비교는 각자의 사용 상황에 맞춰 하는 것을 추천합니다.
하지만 조건이 예측 불가능한경우, 조건 분기는 비쌉니다. 이는 명령 파이프라인의 투기적 실행 (speculated execution) 작업 전체를 잃어버리기 때문입니다. 이진 탐색의 경우에는 남아 있는 목록 중 왼쪽 부분이나 오른쪽 부분을 탐색에 사용하는 것이라 명백하게 패턴을 예측할 수 없습니다. 결과적으로 이런 경우에는 분기 무브가 더 낫게 됩니다.
버전 3
if 문을 완전히 제거해서 비조건 연산들을 늘려 보았습니다.
template <class T> INLINE size_t fast_upper_bound3(const vector<T>& vec, T value)
{
size_t size = vec.size();
size_t low = 0;
while (size > 0) {
size_t half = size / 2;
size_t other_half = size - half;
size_t probe = low + half;
size_t other_low = low + other_half;
T v = vec[probe];
size = half;
low = v >= value ? low : other_low;
}
return low;
}
이번에는 clang이 삼항 연산 low = v >= value ? low : other_low을 조건 무브로 바꾸지 않는 문제가 있습니다. 생성된 어셈블리 코드는 아래와 같습니다.

그래서 우리는 그 부분을 주석 처리하고 choose() 함수 호출로 대신했습니다.choose()는 cmovaeq 명령을 수행하러 인라인 어셈블리를 사용합니다.
template <class T> INLINE size_t choose(T a, T b, size_t src1, size_t src2)
{
#if defined(__clang__) && defined(__x86_64)
size_t res = src1;
asm("cmpq %1, %2; cmovaeq %4, %0"
:
"=q" (res)
:
"q" (a),
"q" (b),
"q" (src1),
"q" (src2),
"0" (res)
:
"cc");
return res;
#else
return b >= a ? src2 : src1;
#endif
}
세번째 시도의 결과는 다음과 같습니다:
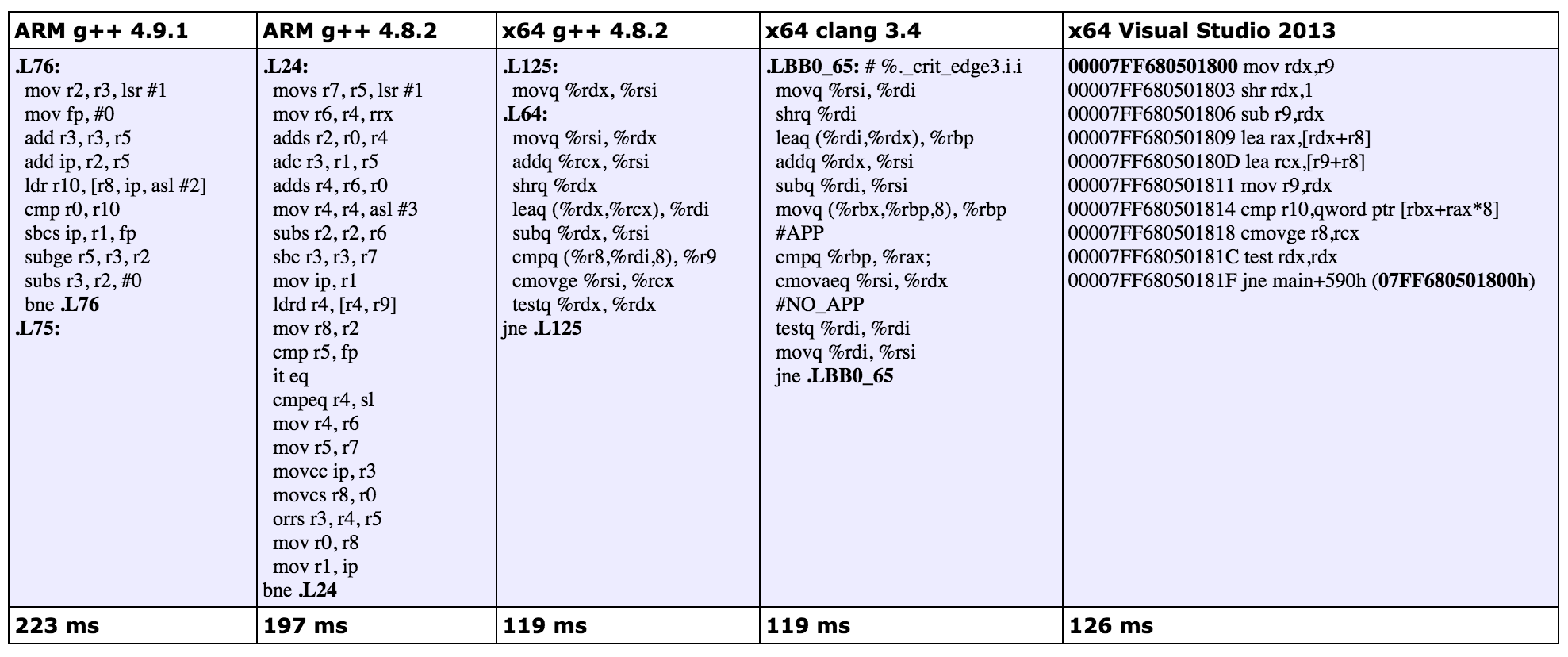
x64 g++ 4.8.2와 x64 clang 3.4에서는 한 줄의 조건 무브 명령을 얻었습니다. 2번째 시도에서는 두 번의 조건 무브 명령이었습니다. C++ 코드의 아래에 한 줄의 조건 대입만 가지고 있기 때문에 이런 결과가 예상되었었습니다.
ARM에서는 어떤 조건 무브는 속도 향상없는 다른 조건 명령으로 변환되었습니다.
버전 3 풀기
리스트가 대부분 길기 때문에 while 반복문을 3개의 반복적인 열로 풀어 보았습니다.
template <class T> INLINE size_t fast_upper_bound4(const vector<T>& vec, T value)
{
size_t size = vec.size();
size_t low = 0;
while (size >= 8) {
size_t half = size / 2;
size_t other_half = size - half;
size_t probe = low + half;
size_t other_low = low + other_half;
T v = vec[probe];
size = half;
low = choose(v, value, low, other_low);
half = size / 2;
other_half = size - half;
probe = low + half;
other_low = low + other_half;
v = vec[probe];
size = half;
low = choose(v, value, low, other_low);
half = size / 2;
other_half = size - half;
probe = low + half;
other_low = low + other_half;
v = vec[probe];
size = half;
low = choose(v, value, low, other_low);
}
while (size > 0) {
size_t half = size / 2;
size_t other_half = size - half;
size_t probe = low + half;
size_t other_low = low + other_half;
T v = vec[probe];
size = half;
low = choose(v, value, low, other_low);
};
return low;
}
이 코드는 x64 g++에서만 동일한 속도를 보였고 나머지에선 소폭의 성능 향상이 있었습니다.
우리는 -O3 플래그 (스피드 최적화) 위에 -Os (용량 최적화)의 효과도 테스트하고자 했으며, ARM과 x64에서 아래의 결과를 얻었습니다.

루프 푼 시도에서는 어셈블리 코드를 생성하지는 않았습니다.
정리
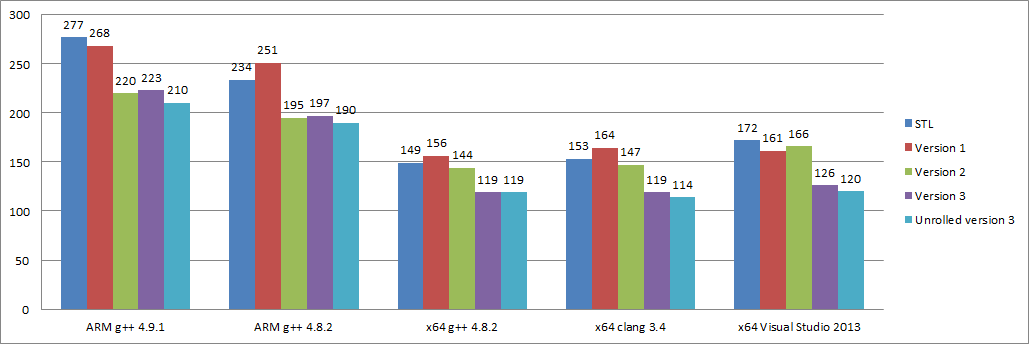
다양한 시도에 대한 전체 벤치마크는 다음과 같습니다.

아키텍쳐별 벤치마크
버전 별 벤치마크
마지막 생각
우리는 STL 보다 평균 24% 실행 시간이 빠른 이진 탐색을 개발했습니다.
(76% + 81% + 80% + 75% + 70%) / 5 = 76%
우리는 잘못 예측된 분기의 비용을 확인했고 대신에 조건 무브를 컴파일러가 사용하게끔 단서를 주는 법을 보았습니다. 이런 단서를 주는 것은 어려운 것이고 생성된 어셈블리 코드를 검증할 필요가 있습니다.
어떤 이진 탐색 알고리즘은 짧은 선형 탐색으로 끝나기도 합니다. 우리의 루프 풀기 시도에서 루프 풀이하지 않은 추가적인 탐색을 선형 탐색으로 대신했습니다. 일반적인 경우 1% 내의 작은 성능 향상이 있었지만, 많은 경우에 속도 저하가 발생했습니다. 우리는 어떤 입력에서도 빠른 최적화를 원했기에 이를 폐기했습니다.
우리는 보간된 이진 탐색(interpolated binary search)도 실험했습니다. 목록을 리스트에 남아있는 제일 왼쪽의 값과 제일 오른편의 값을 보고 분할할 위치를 추정합니다. 이것은 정수 나눗셈을 요구하는데 굉장히 비싼 명령입니다. 우리는 목록의 값 분포가 매우 동질적일 때만 이기는 것을 발견했다. 최악의 경우에서는 실행에서 우리의 O(log2(n)) 보다 나빴습니다.
다음 단계
성능이 좋은 모바일 데이타베이스가 필요한데 아직 Realm을 사용해본 적이 없으신가요? iOS와 안드로이드 최신버전을 받아보시기 바랍니다.
이런 최적화를 하는데 관심이 있으신가요? Realm 오픈 소스 프로젝트에 참여해보세요!
소스 코드
전체 코드는 여기에서 파일로 받을 수 있습니다.
컨텐츠에 대하여
이 컨텐츠는 저자의 허가 하에 이곳에서 공유합니다.


