기본적인 Realm 스레딩에 관한 글을 읽으면 Realm의 여러 기능과 스레드를 함께 사용하는 것이 생각보다 어렵지 않고 간단하다는 것을 알게 되지만, 여전히 궁금함이 남아 있을 수 있습니다.
혹시 Realm이 내부적으로 어떻게 동작하는지 알고 싶으신가요? 이론적인 내용과 동작 원리, 그리고 이런 동작 원리를 채택한 이유를 모두 알고 싶다면 이 글이 제격입니다. 어떻게 Realm이 동작하는지, 그리고 왜 그렇게 동작하는지 상세하고 자세한 내용을 설명하겠습니다.
“복잡함은 적입니다. 바보라도 복잡하게 만들 수는 있습니다.
다만 어떤 것을 단순하게 만드는 것이 어렵습니다.”
- 리처드 브래슨 경
이 문구는 딱 우리가 지향하는 바입니다. 우리는 개발자에게 어려운 분야를 골라서 사용하기 쉽게 만들었습니다. 스레드, 동시성, 데이터 일관성 등 모든 부분을 올바르게 만들기는 쉽지 않은 일입니다. 동시성을 설계하기 위해서는 사람의 뇌가 수많은 시행착오를 겪어야 하며, 결국에는 바보 같은 실수를 할 수도 있습니다. 따라서 Realm은 여러분이 봉착한 이슈를 해결하려는 목표를 가지고 있습니다.
Realm의 기반
Realm은 C++로 처음부터 만든 MVCC 데이터베이스입니다. MVCC는 멀티버전 동시성 제어(Multiversion Concurrency Control)를 뜻하죠.
첫눈에는 복잡해 보이지만 자세히 살펴보면 무언가 느껴지기 시작하실 겁니다. 💡
MVCC는 중요한 동시성 이슈를 해결합니다. 어떤 데이터베이스이든 누군가가 데이터베이스로부터 뭔가 읽고 있는데 동시에 다른 사람이 기록할 경우가 있습니다. (예를 들어 다른 스레드에서 같은 데이터베이스에 읽고 쓸 수도 있죠) 이는 데이터의 일관성을 해치거나 레코드를 읽는 동안 쓰기 연산이 부분적으로만 완료되는 결과를 낳을 수 있습니다. 데이터베이스가 이를 허용하면 반환받을 결과는 일관성이 없게 됩니다.
말할 것도 없이 이런 상황은 좋지 않습니다.
이런 경우 여러분이 데이터를 보는 관점은 데이터베이스와는 다르게 되므로 불일치가 생겨나고 데이터를 신뢰할 수 없게 됩니다.
자연히 데이터베이스에서 ACID를 지원하기를 바라게 됩니다.
- 원자성 (Atomic)
- 일관성 (Consistent)
- 고립성 (Isolated)
- 지속성 (Durable)
이런 읽기/쓰기 문제를 해결하는 방법은 여러 가지입니다. 가장 일반적인 것은 데이터베이스에 락을 사용하는 것으로, 위의 상황에서는 DB에 쓰기가 진행할 때마다 락을 적용합니다. 락은 결국 쓰기가 완료될 때까지 계속해서 읽기 연산을 막습니다. 읽기-쓰기 락이라고 부르는 이 락은 일반적으로 매우 느리죠.
이러한 사실이 Realm의 MVCC 설계 결정에 영향을 미쳤습니다.
Realm은 MVCC 데이터베이스입니다.
Realm과 같은 MVCC 데이터베이스는 다른 접근법을 취합니다. 매번 연결되는 스레드는 특정한 시점의 데이터 스냅샷을 보게 됩니다.
이 사실이 의미하는 바는 무엇일까요?
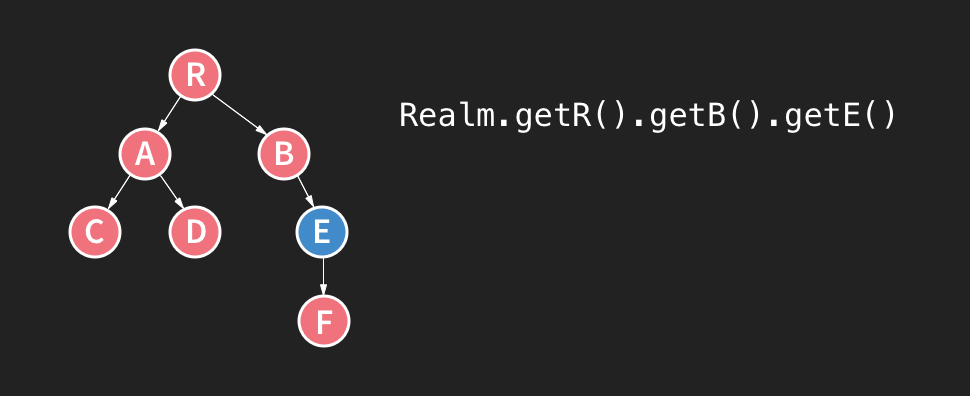
MVCC는 Git과 같은 소스 컨트롤 알고리즘에 사용되는 설계 선택입니다. Git이 가지는 브랜치와 원자적 커밋의 개념과 유사한 방식으로 Realm의 내부를 시각화할 수 있습니다. 즉, 전체 데이터를 복사하지 않고도 많은 브랜치(데이터베이스 버전)와 작업할 수 있다는 것입니다. 단, Realm은 순수한 MVCC 데이터베이스와는 조금 다릅니다. 순수한 MVCC는 git처럼 트리의 여러 후보가 HEAD가 될 수 있지만, Realm에서는 어떤 시점에 하나의 작성자만 조작할 수 있으며 항상 마지막 버전을 이용하게 되며, 이 버전 앞에 있는 것은 사용할 수 없습니다.
또한, Realm은 거대한 트리 데이터 구조(정확하게는 B-tree)와 유사하고 어떤 시점에도 아래에 R이라 표기된 (Git의 HEAD 커밋과 유사한) 최상의 수준의 노드를 얻게 됩니다.
변경이 발생하면 쓰기 시 복사(copy-on-write) 행위가 이뤄집니다. 쓰기 시 복사는 트리를 포크해서 기존 데이터를 수정하지 않고 쓰기 작업을 한다는 의미입니다.
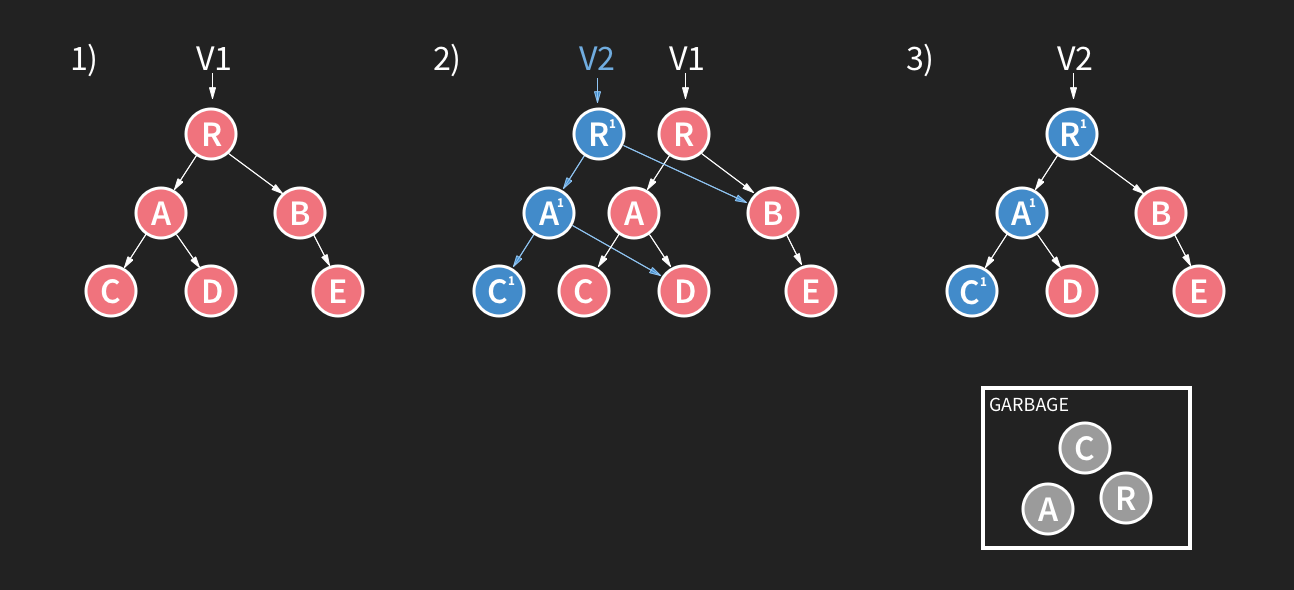
이런 접근 방식을 사용하면 쓰기 트랜잭션에 잘못이 있더라도 원래 데이터는 손상되지 않습니다. 즉, 다른 곳에 기록했기 때문에 최상위 수준 포인터는 여전히 손상되지 않은 데이터를 가리키고 있습니다. 쓰기는 Realm은 모든 것이 디스크에 작성되고 데이터가 안전한지 확인하는 두 단계 커밋(two-phase commit) 개념으로 식별됩니다. Realm은 이렇게 식별이 이뤄진 이후에만 포인터를 움직이고 “됐어, 이게 공식적인 새 버전이야.”라고 말하죠. 따라서 최악의 일이 쓰기 트랜잭션에서 일어나도 갱신 중인 데이터만 잃을 뿐, 전체 Realm 데이터베이스에는 손상이 없게 됩니다.
Realm 오브젝트와 관계
Realm에서 또 주목할만한 점은 객체의 관계가 네이티브 레퍼런스라는 점입니다. 무복제(zero-copy) 아키텍처 때문에 메모리 풋프린트(close-to-zero memory footprint)를 거의 가지지 않습니다. 이는 Realm 객체가 직접 데이터베이스의 데이터에 연결된 하부 데이터베이스의 네이티브 롱 포인터와 이야기하기 때문에 가능합니다.
Realm은 기존 데이터베이스 접근 기술에서 발생하곤 하는 느린 셔플링이나 느린 메모리 복사가 일어나지 않도록 방지합니다.
이게 왜 중요할까요?
그 이유는 단순합니다. 참조된 객체를 얻기 위해 추가적인 작업을 할 필요가 없다는 것이죠. 참조 객체는 특급 시민(first-class citizen)이므로 상당한 성능 개선이 가능합니다. 추가적인 질의나 비싼 조인을 할 필요가 없죠.
게다가 모든 모바일 단말들이 가지는 메모리 제약 문제도 해결합니다. Realm은 메모리를 낮게 유지하므로 메모리 부족(out-of-memory) 상황과 다른 메모리 문제들을 방지할 수 있습니다.
무복제가 무엇이고 왜 빠른가요?
Realm은 무복제 아키텍처에 기반을 두고 있습니다. 무복제의 강점과 중요성을 이해하기 위해 먼저 기존 ORM(object-relational mappers)들에서 어떻게 데이터를 가져오는지 간단히 살펴보겠습니다.
ORM, 코어데이터 등에서 전통적인 객체 가져오기
대부분의 경우 데이터베이스 파일에 저장된 데이터를 디스크에 가지고 있습니다. 개발자는 데이터를 ORM, 코어 데이터와 같은 영속 메커니즘에 안드로이드, iOS와 같은 플랫폼의 네이티브 객체를 통해 요청합니다. 한 시점에 영속 메커니즘이 요청을 SQL 문으로 변환하고 아직 생성되지 않았다면 데이터베이스 연결을 생성하고 디스크로 보내며, 질의를 수행하고 질의에 해당하는 줄의 데이터 전체를 읽어오며 메모리를 할당해서 전부 다 메모리에 넣습니다. 이때 데이터 포맷을 메모리에 저장할 수 있도록 역직렬화(deserialize)를 해야 합니다. 다시 말해 CPU가 다룰 수 있도록 비트를 정렬해야 하죠. 마지막으로 데이터를 언어 수준 타입으로 변환한 다음, 요청자에게 POJO, NSManagedObject 등 플랫폼이 상호작용할 수 있는 객체로 돌려줘야 합니다. 영속 메커니즘에 자식이나 리스트 참조가 있다면 더욱 복잡해집니다. 어떤 영속 메커니즘을 사용하고 어떤 설정을 했는지에 따라 다르긴 하지만 이런 순환 작업이 반복적으로 이뤄져야 합니다. 만약 자신만의 해법을 사용하고 있다 하더라도 이런 상황은 여전히 남아있을 겁니다.
결론적으로 데이터를 앱의 데이터 구조에 넣기 위해서는 많은 것을 해야 합니다.
Realm 객체 가져오기
Realm의 접근법은 좀 다릅니다. 지금부터는 Realm이 무복제 아키텍처를 선택한 이유를 설명하겠습니다.
데이터베이스 파일은 항상 메모리 맵(memory‑map)되어 있으므로 Realm은 전체적인 복제 과정을 생략할 수 있습니다. 또한, Realm은 메모리 맵이 되지 않은 경우에도 파일이 이미 메모리에 있을 때처럼 어떤 오프셋에 접근할 수 있는데, 이를 가상 메모리라고 합니다. 이것이 코어 Realm 파일 포맷의 중요한 설계 결정 부문이죠. 덕분에 파일을 비직렬화 과정없이 메모리에서 읽을 수 있습니다. Realm은 단순히 파일에서 데이터를 찾기 위해 오프셋을 계산하고 자료 구조(POJO, NSManagedObject 등)의 접근자에게 데이터를 반환합니다. 이 방식은 매우 효율적이고 속도가 빠릅니다.
특히 Realm은 B 트리와 비슷한 구조에 관계된 객체가 인덱싱되므로 관계를 매우 빠르게 다룰 수 있습니다. 이 작업은 질의보다 빠르며, ORM처럼 전체적인 다른 질의를 수행하지 않아도 단순히 관계 객체에 대한 네이티브 포인터를 사용하는 것만으로 끝납니다.
자동 갱신되는 객체와 쿼리
무복제 아키텍쳐는 속도만 빨라지는 것이 아닙니다. Realm 객체와 질의는 하부 데이터에 따라 라이브로 자동 갱신되는 뷰입니다. 즉, 결과를 다시 가져올(re-fetch) 필요가 없다는 뜻이죠. 수정된 객체는 질의의 결과에 즉각 반영됩니다.
코드와 함께 보시죠.
Java
RealmResults<Dog> puppies = realm.where(Dog.class).lessThan("age", 2).findAll();
puppies.size(); // => 0
realm.beginTransaction();
Dog dog = realm.createObject(Dog.class);
dog.setAge(1);
realm.commitTransaction();
puppies.size(); // => 1
// 다른 질의에서 개의 나이를 변경합니다.
realm.beginTransaction();
Dog theDog = realm.where(Dog.class).equals("age", 1).findFirst();
theDog.setAge(3);
realm.commitTransaction();
// 원래 개는 자동 갱신됩니다.
dog.getAge(); // => 3
puppies.size(); // => 0
Swift
let puppies = realm.objects(Dog).filter("age < 2")
puppies.count // => 아직 개가 Realm에 추가되지 않았기 때문에 0
let myDog = Dog()
myDog.name = "Rex"
myDog.age = 1
try! realm.write {
realm.add(myDog)
}
puppies.count // => 실시간으로 1로 갱신됩니다.
// 다른 질의에서 개에 접근합니다
let puppy = realm.objects(Dog).filter("age == 1").first
try! realm.write {
puppy.age = 3
}
// 원래 개 객체는 자동 갱신됩니다.
myDog.age // => 3
puppies.count // => 0
Dog 객체를 생성하고 Realm에 커밋하자마자 puppies라는 질의 결과는 자동으로 새로운 값으로 갱신됩니다. 다른 질의에서 개가 변경돼도 원래 개 인스턴스는 자동으로 갱신되죠.
이런 자동 갱신 특성은 다른 스레드에서 Realm 데이터를 갱신할 때도 적용됩니다. 객체가 다른 스레드에서 갱신되면 스레드 로컬 객체들은 거의 실시간으로 갱신됩니다. (정확히 말하자면 현재 스레드에서 다른 일을 하고 있다면 갱신은 런 루프의 다음 반복에서 이루어집니다) Realm#refresh() 연산을 사용해 강제로 데이터를 갱신할 수도 있습니다.
자동 갱신은 모든 Realm 객체들과 질의 결과 인스턴스에 적용됩니다.
런 루프의 다음 반복이나 Realm의 refresh 메서드가 호출될 때 Realm 인스턴스는 가능한 최근의 제일 높은 포인터, 즉 가장 최근의 Realm 데이터로 이동합니다.
이런 Realm 객체와 질의 결과의 특성은 Realm을 빠르고 효과적이게 할 뿐 아니라 작성해야 할 코드도 더욱 단순하고 반응적으로 바꿉니다. 예를 들어 질의 결과를 사용하는 UI가 있는 경우, Realm 객체나 질의 결과를 어떤 필드에 저장하고 매번 접근하기 전에 데이터 자체가 갱신되었는지 확인하지 않아도 됩니다.
Realm 노티피케이션을 구독하면 Realm 질의 결과를 다시 가져오지 않으면서 Realm 데이터가 갱신된 시점을 파악해서 언제 앱의 UI를 갱신해야 할지 알 수 있습니다. 이 기능은 Java, Objective‑C, Swift, JavaScript, 모든 Realm 제품에서 사용 가능합니다.
Realm 데이터가 바뀔 때 통보받기
객체의 자동 갱신 기능이 훌륭하지 않나요? 하지만 언제 변경이 되고 언제 반응해야 할지 모른다면 유용하지 않을 겁니다. Realm은 이미 노티피케이션 메커니즘을 탑재하고 있으므로 Realm 데이터 변경에 쉽게 반응할 수 있습니다.
UI 값을 표시하기 위해 UI 스레드에서 사용되는 객체가 있다고 생각해 보겠습니다. 백그라운드 스레드는 어떤 연산 과정에서 이 객체를 변경합니다. 대부분 즉각적으로, 정확하게는 다음 런 룹 반복에서 UI 스레드 객체의 데이터가 갱신됩니다. 이때 객체는 무복제 아키텍처로 코어 데이터베이스에 직접 연동된다는 점을 기억하세요.
백그라운드 스레드는 UI 스레드에 Realm 변경 리스너를 통해 변경을 알리는 노티피케이션 메시지를 보냅니다. 이 기능은 Java, Objective‑C, Swift, JavaScript, 모든 Realm 제품에서 사용 가능합니다. 이 시점에서 아래 다이어그램처럼 UI 스레드가 새 데이터를 보여주기 위해 뷰를 갱신합니다.

안전한 스레드 모델
아래와 같은 질문이 자주 옵니다.
“왜 Realm 객체는 스레드 경계를 넘지 못하나요?”
좋은 질문입니다. 그 이유는 격리와 데이터 일관성 때문입니다.
Realm은 무복제 아키텍쳐이므로 모든 객체는 라이브이고 자동 갱신됩니다. Realm이 스레드를 넘어서 객체를 전달하도록 허용하면 다양한 스레드에서 확정되지 않은 시점에 데이터 수정을 시도할 수 있으므로 데이터 일관성을 지키는 것이 불가능해집니다. 다른 스레드가 읽고 있을 때 한 스레드에서 값을 쓸 수도 있고 그 반대 경우도 가능하죠. 이렇게 많은 문제가 발생하기 쉽고 어떤 스레드가 정확한 객체 데이터를 가졌는지도 신뢰하기 어렵습니다.
이 문제에 대한 해결 방법은 많지만, 보통 객체, 변경자, 접근자에 락을 적용하는 방식으로 해결하죠. 하지만 락은 성능을 제한하는 병목 현상의 원인이 됩니다. 성능 문제를 접어두더라도 락은 백그라운드 쓰기 트랜잭션이 길어지면 UI에서 읽기 트랜잭션을 막는다는 치명적인 문제를 일으킵니다. 만약 락을 활용하면 빠른 속도라는 장점과 Realm이 제공하는 데이터 일관성 보장이라는 기능마저 잃게 됩니다.
Realm의 유일한 제약은 스레드 간에 Realm 객체를 넘길 수 없다는 것입니다. 만약 같은 데이터가 다른 스레드에서 필요하다면 그냥 다른 스레드에서 데이터에 대해 질의를 하는 것이 좋습니다. 더 나은 방법은 Realm의 반응형 아키텍처를 이용해 변화를 관찰하는 것입니다. 모든 객체는 스레드 사이에서 항상 최신이라는 점을 기억해 주세요. Realm은 데이터가 변경될 때마다 통지하므로 단지 그 변화에 반응하면 됩니다. 👍
Realm과 안드로이드
Realm은 스레드에 제한적이기 때문에 어떻게 안드로이드 프레임워크 스레드 환경에서 Realm이 동작하는지 설명하겠습니다.
Realm과 안드로이드 프레임워크 스레드
Realm과 안드로이드 백그라운드 스레드를 함께 사용한다면 스레드에서 Realm을 확실히 열고 닫아야 합니다. 문서의 안드로이드에서 작동하기를 참고하세요.
Realm이 안드로이드 메인 스레드에서 작동할 때 ANR(애플리케이션 응답 없음, Application Not Responding)을 피하려면 비동기 API를 사용하는 것이 좋습니다.
Realm을 메인 스레드에서 사용하고 싶은데 할 수 있나요?
몇몇 명령은 메인 스레드에서 사용해도 괜찮고 어떤 명령은 그렇지 않습니다.
언제 메인 스레드에서 Realm을 사용하면 안되나요?
이는 몇몇 요소에 따라 다릅니다. 메인 스레드에서 수행해도 될지 고민하지 않으려면 안드로이드에서 Realm을 사용할 때 따라야 할 공통 규칙을 따르는 것이 좋습니다.
Realm의 비동기 API 사용하기.
질의와 트랜잭션에 Realm 비동기 API 사용하기
Realm의 비동기 질의와 트랜잭션 지원 모두 매우 쉬운 패턴으로 비동기 연산을 간단히 구성할 수 있습니다.
Realm의 비동기 질의
비동기 질의를 보면 내부 스레드 모델이 현재 어떻게 노출되어 있는지 이해하기 쉽습니다.
Realm 질의 메서드는 findAllAsync()처럼 Async()가 끝에 붙어 있고, 바로 RealmResults나 RealmObject을 반환합니다. 이 메서드들은 자바의 Future와 매우 흡사한 프로미스로, 질의는 백그라운드 스레드에서 수행됩니다. 질의가 백그라운드 스레드에서 완료되면 반환된 객체는 질의의 결과로 갱신됩니다.
비동기 질의의 예제를 보여 드리겠습니다.
private Dog firstDog;
private RealmChangeListener dogListener = new RealmChangeListener() {
@Override
public void onChange() {
// 질의가 완료되면 매 갱신마다 호출됩니다.
// 이제 결과를 사용할 수 있습니다.
Log.d("Realm", "개를 찾았거나 갱신됐습니다!");
}
};
앱의 다른 부분(예제에서는 onCreate)에 아래의 코드를 넣어야 합니다.
firstDog = realm.where(Dog.class).equalTo("age", 1).findFirstAsync();
firstDog.addChangeListener(dogListener);
onPause() 메서드에 아래의 코드를 넣습니다.
firstDog.removeChangeListener(dogListener);
findFirstAsync는 onCreate()에서 호출합니다.
findFirstAsync() 호출은 RealmResults의 첫 번째 RealmObject를 반환하며, 이 메서드는 즉시 반환됩니다. 질의가 완료될 때까지 firstDog의 데이터가 형태에 맞게 채워지지는 않습니다. 비동기 연산이 끝날 때 알림을 받기 위해서 firstDog RealmObject에 대해 변경 리스너를 추가한 것을 볼 수 있습니다. 이 리스너는 다른 리스너와 같죠. 나중에 onPause() 메서드에서 리스너를 지울 수 있도록 레퍼런스를 가지는 것이 좋습니다.
RealmObject와 RealmResults가 로딩되었는지 확인하기 위해 언제든지 isLoaded() 메서드를 사용할 수 있습니다. (예: firstDog.isLoaded())
비 안드로이드 루퍼 스레드 경고: 비동기 질의의 결과를 지속해서 전달하려면 Realm 핸들러를 사용해야 합니다. 루퍼 없이 스레드 내부의 열려있는 Realm을 사용하는 비동기 질의는 IllegalStateException을 발생시킵니다.
비동기 트랜잭션으로 Realm에 데이터 쓰기
새로운 비동기 트랜잭션을 사용하면 Realm에 정말 쉽게 비동기로 쓸 수 있습니다. 비동기 트랜잭션 지원은 현재 executeTransaction과 같은 방법으로 작동합니다. 같은 스레드에서 Realm을 여는 대신 백그라운드 Realm을 다른 스레드에서 열고, 트랜잭션 성공과 실패 시점에 통보받으려면 콜백을 등록할 수 있습니다.
비동기 트랜잭션은 다음처럼 간단하게 구현합니다.
realm.executeTransactionAsync(new Realm.Transaction() {
@Override
public void execute(Realm realm) {
Dog dog = realm.where(Dog.class).equalTo("age", 1).findFirst();
dog.setName("Fido");
}
}, new Realm.Transaction.OnSuccess() {
@Override
public void onSuccess() {
Log.d("REALM", "All done updating.");
Log.d("BG", t.getName());
}
}, new Realm.Transaction.OnError() {
@Override
public void onError(Throwable error) {
// 트랜잭션이 자동으로 롤백되고 여기에서 정리 작업을 합니다
}
});
위 코드의 마지막 두 파라미터, new Realm.Transaction.OnSuccess와 new Realm.Transaction.OnError는 선택적입니다. 콜백에서는 트랜잭션이 끝났는지 혹은 에러가 났는지 개발자가 통보받을 수 있습니다. executeTransactionAsync 메서드는 백그라운드 스레드에서 수행될 Realm.Transaction 객체를 받습니다.
execute 메서드를 재정의해서 트랜잭션에 수행할 일을 이 메서드에 작성합니다. 이 코드는 백그라운드에서 수행될 겁니다. execute 메서드는 함께 일할 Realm 인스턴스를 제공하는데, executeTranscationAsync 메서드에서 생성된 이 Realm 인스턴스는 백그라운드 스레드를 위한 인스턴스입니다. 간단히 이 Realm 인스턴스를 이용하여 관심 있는 아이템을 찾고 갱신하면 됩니다. 우리 예제에서는 개 아이템이겠죠? executeTransactionAsync 메서드는 beginTransaction과 commitTransaction을 백그라운드에서 수행하므로 이를 수행할 필요가 없습니다.
연산이 끝나면 Transaction.OnSuccess 클래스의 onSuccess 메서드가 수행되며, 에러가 발생했다면 예외 처리를 위해 onError로 전달됩니다. onError가 수행될 때는 에러로 인해 Realm 트랜잭션이 롤백 된다는 점을 기억하세요.
마지막으로 Realm은 Transaction에 대한 강한 참조를 가집니다. 만약 트랜잭션을 액티비티나 프래그먼트의 정지 등과 같은 이유로 취소해야 한다면, 트랜잭션 인스턴스의 결과를 간단히 대입하고 아무 데서나 취소해도 됩니다.
RealmAsyncTask transaction = realm.executeTransactionAsync(...);
...
// 트랜잭션 취소하기 - onStop()이나 다른 곳
if (transaction != null) {
transaction.cancel();
}
Realm 비동기 트랜잭션 지원을 위해서는 Realm의 핸들러를 콜백에 전달해야 합니다. 비 루퍼 스레드에서 열린 Realm을 비동기 쓰기에 전달하면 노티피케이션을 받을 수 없습니다.
** 모든 곳에는 예외가 있기 마련이죠. 속도에 대해 알 필요가 있다면 코드에서 System.nanotime로 벤치마킹을 할 수 있습니다. VM이 랜덤하게 동작하며 가비지 컬렉션을 호출한다는 점에 주의하세요. System.nanotime는 기본적인 측정지로 사용하는 편이 좋습니다.
적은 저항, 적은 오버헤드, 많은 이득
Realm은 매일 매일의 개발 환경을 도울 수 있도록 개발되었습니다.
우리는 Realm을 영속 계층과 관련된 개발을 더 쉽고 즐겁게 할 수 있도록 개발하고 있습니다. 많은 개발자들이 Realm으로 데이터 일관성, 성능, 스레드 등 매우 어려운 문제들을 해결하고 있죠. 단 한 가지 주의점은 스레드 사이에 객체를 전달하지 않는 것뿐입니다.
일관성을 위해 단지 스레드 제약만이 있고, 성능상의 이점과 반응형 프로그래밍 특성을 얻을 수 있다면 나쁜 취사선택은 아니리라 생각합니다.
컨텐츠에 대하여
이 컨텐츠는 저자의 허가 하에 이곳에서 공유합니다.


