

“We value working software over comprehensive documentation” is what the manifesto for Agile software development says, with the typical misinterpretation of these few words being “don’t write documentation.” Of course, that’s not what the manifesto says, and “no documentation” certainly wasn’t the intent. It seems that many software teams have lost the ability to communicate what it is they are building and it’s no surprise that these same teams often seem to lack technical leadership, direction, and consistency. This session from GOTO London will look at various approaches and tools that you can use to visualize, document, and explore your software architecture in order to build a better team.
Introduction (0:00)
Today we’ll be taking a short tour of visualizing, documenting, and exploring software architecture, starting with a short example:
Example
Imagine we’ve invented teleporters, and I teleport you here.

Where are you? France? Close, but not quite.
This is what happens when new people are added into a code base. They get thrown into the middle of a project and end up somewhat lost.
How do we solve this problem? How do we figure out where we are?
We zoom out, we use technology, we open up the maps on our phone and start zooming out.

This may be slightly better, but we still aren’t quite sure where we are, so we need to zoom out again.
We may be able to see where we are, but there is a lot of cluttering on the map, and it’s not very clear to see whats going on. In a program like Google Maps, we can reduce the amount of information to make the picture a bit clearer.
Now that the image is a bit clearer, we can start to see the names of places and where some of the bits and pieces of the landscape are. However, if you’ve never hear of Jersey before, this is still kind of useless forcing you to zoom out a few more times.
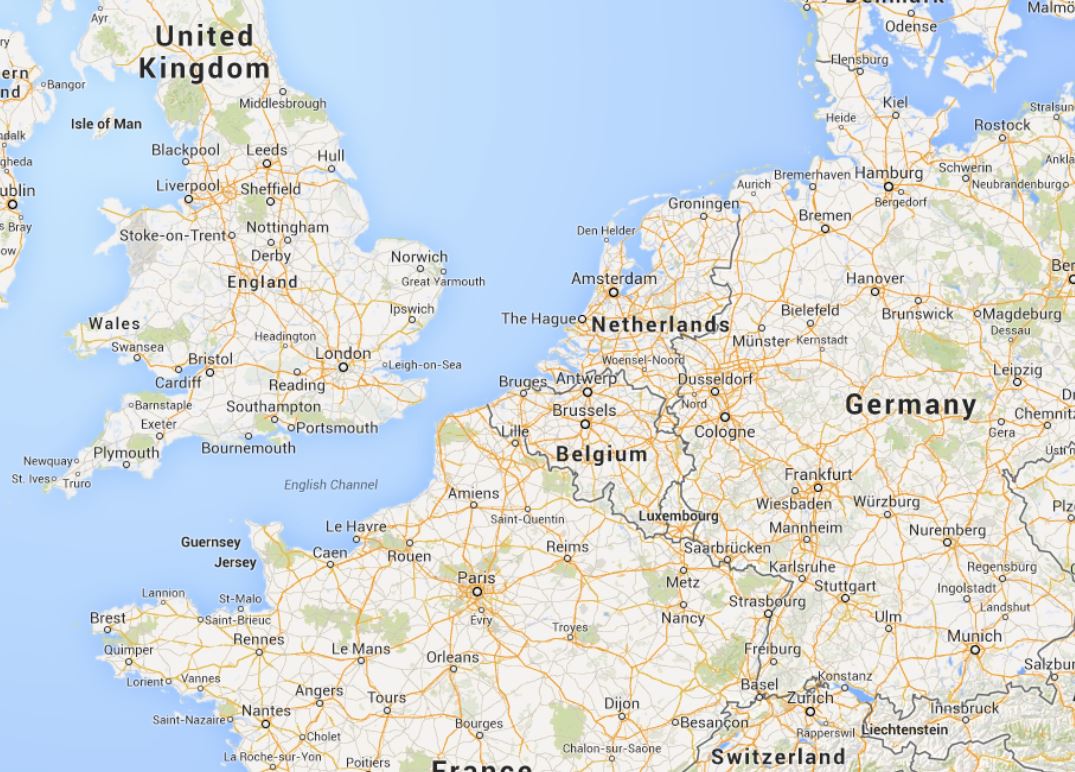
Now that we’ve zoomed all the way out, you can see that Jersey is a small island of the coast of France. If you come and visit Jersey, which you should because it’s lovely, when you come through the airport you can get a map. The map is divided up and tells you enough information to get around and find the major sites. It doesn’t tell you everything however. It won’t list every street, with every building on every street either. There may be a zoomed in area of the main city with more detail, but it’s a representation and isn’t completely accurate.
The thing these maps have in common is that they show points of interest. It shows you what you would really want to see if you visit Jersey. Contrast this map with an ordnance survey map, which shows a very detailed version of Jersey with contours of different types of land. To read this map you would need some sort of intelligence and some help getting started to interpret it.
Both maps however show selected highlights and points of interest.
With these points of interest, there are history lessons that come with them along with other detailed information about the location, which could all be found in guidebooks.
Visualization(4:08)
I run a visualization workshop with software teams all over the world and we give people requirements and then give them 90 minutes to draw some pictures, and groups come up with all kinds of crazy diagrams:
I’m sure these types of diagrams all look familiar.
Oftentimes when running the workshop I hear people say as they draw:
“…this doesn’t make sense but we’ll explain it later when we do our presentation or something…“
This is fine in some instances, but we don’t always present our own diagrams. I like to remind teams of this by having two teams swap diagrams, and because they weren’t part of the conversation creating those diagrams, they have no idea what’s going on. Teams can’t understand the color coding or the shapes or the lines and basically none of the notation makes any sense whatsoever.
Teams always say it was an easy exercise but yet diagrams are always a mess. We don’t really know what to draw, the levels of details, shapes, notations, whether we should use UML etc…
Who still uses UML?
I’ve asked this question around the world and UML is massively falling out of fashion. I have no evidence to back any of this up, this is all completely anecdotal, but I’m seeing more and more teams who have no UML skills. Personally, I use UML, but I use it sparingly for small parts of a software system such as a class hierarchy.
If you Google search a software architecture diagram you get this:

Page after page after page of essentially pretty-colored block pictures, the sorts of diagrams you can create in Visio or PowerPoint, and these are exactly the types of diagrams I see when I go and visit organizations, and half the pictures simply don’t make any sense.
I’ve run this workshop for about 10,000 people now, all around the world, and nobody does it sufficiently well the first time around.
Notation Tips(6:58)
One of the great things Agile has done is it’s made us more visual. Whenever I go and visit Agile organizations, they have camera boards, storywalls and information dashboards, demonstrating that we have become awesome at visualizing and processing the way we work, however we have totally forgotten how to draw pictures of the things we are building. This is simply about good communication. If you want to move fast as a team, if you want business agility, then you need to communicate well.
Here are some really simple tips around notation.
- Put titles and pictures
- Make sure your arrows are annotated
- Make sure your arrows point one way
Responsibilities
The notation around drawing architecture diagrams is easy to fix. One of the key points is responsibilities. We often joke that naming is hard in software, so it doesn’t make sense that most of our architecture diagrams are essentially just a collection of named boxes because this creates a huge amount of ambiguity. A simple fix for this is to simply add more text to your diagrams.
Here’s a really simple example.
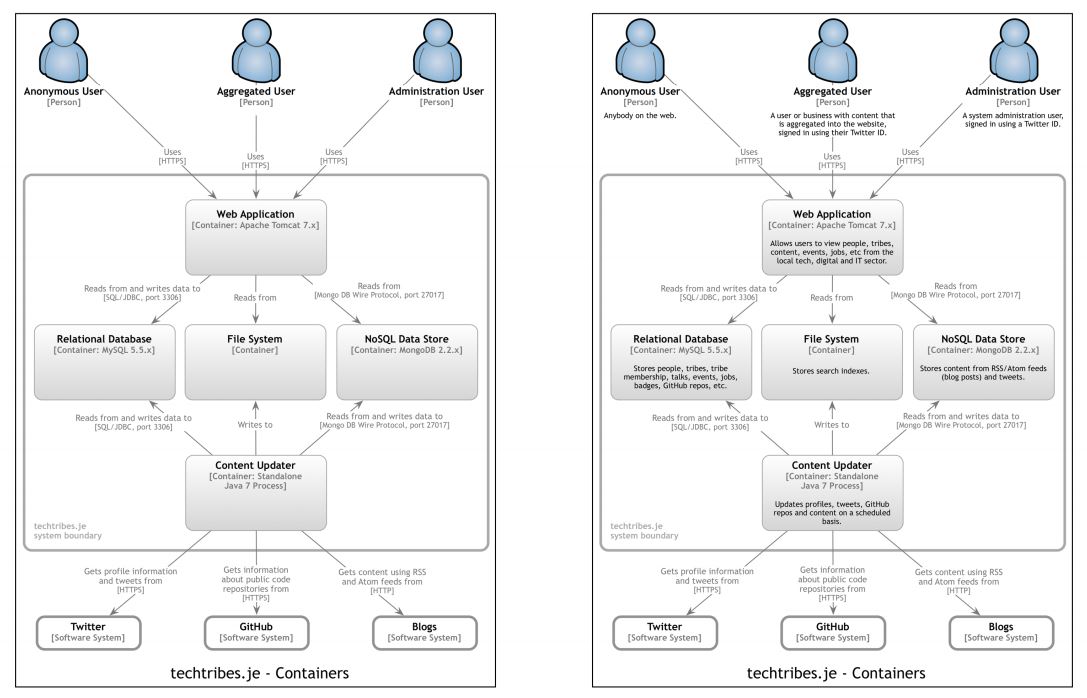
Here are two versions of the same diagram. The one on the right has more text that allows us to see things such as the responsibilities of the building blocks.
In terms of content, you can’t show everything on a single picture when drawing architecture diagrams, which is why people talk about things like views, viewpoints and perspectives. Philippe Kruchten’s 4+1 model is a book that details how to take these points into consideration.
Logical architecture diagrams
A problem with a lot of view catalogs is that they have a logical view of a system separate to the development view of the system. The logical view is often either the functional, logical, or conceptual building blocks of the system, and then there is a separate entity that refers to how we are building the system.
I often find, when I go to organizations, that their nice, fluffy, logical architecture diagrams never match the code they are made to represent. If an architecture diagram doesn’t match the code it’s simply lying to me. George Fairbanks calls this the “model - code gap.”
When discussing architecture, we use abstract concepts such as modules, components or services, but we don’t have these things in our programming languages. For example, in Java there is no ‘layer’ keyword, but we create components and layers by assembling classes, interfaces and packages together.
The ultimate goal of having a discussion like this is to eventually have a set of diagrams that actually reflects code. Before we can tackle that problem however, we need to deal with the fact that we still don’t have any sort of consistent, standard language for talking about software architecture.
Examples(10:19)

The image above is clearly a map of London. If you look at the map you are able to recognize the blue thing that stretches across the map as a river, specifically the River Thames. We all know that a river is a body of water flowing in some direction. Based on this information we can now go find other rivers.
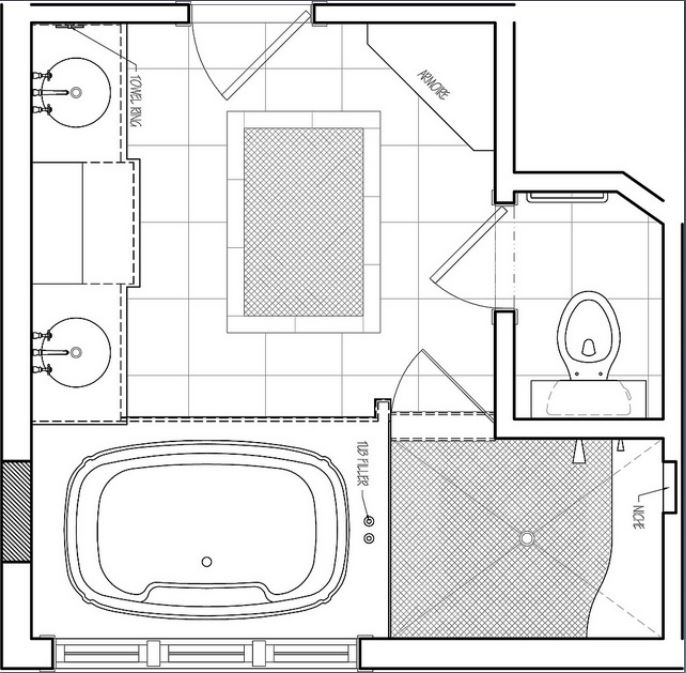
We can see in this next picture that we are looking at the floorplan of a bathroom. In this floorplan it is easy to find the toilet, and we all know what a toilet is and can find other toilets on other floorplans.

There a few ways for representing circuits in electrical engineering. The top image has the cartoon pictorial representation of circuit elements and the bottom shows a schematic version. Most people can identify the squiggly line as a resistor and know that a resister slows down currents, and then can go forward to use this knowledge to find other resistors and build more circuits. An engineer could go through a box of components and find the resistors and use the color coding to identify how strong of a resistor it is.
To ramp up the complexity of this example lets take a look at the following diagram.
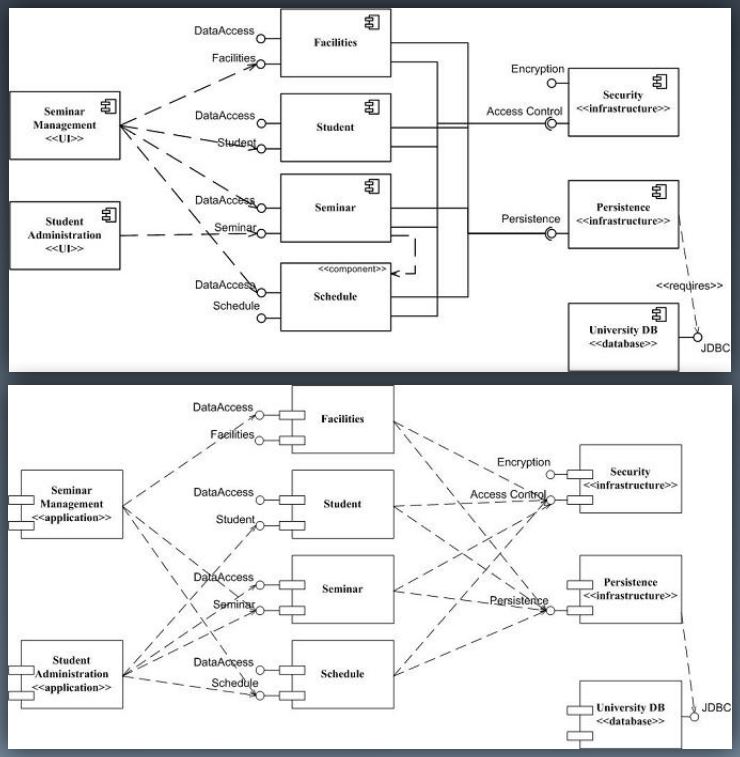
Looking at this diagram we really can’t tell what it is. There are two UML diagrams, where the boxes represent components. Components are logical, abstract, functional, building blocks. In this example one box is a stereotyped database and another is a JDBC interface which makes it sound like a database component. Others represent UIs or applications, and items in the middle represent business components. Where do these components run? Do they run in the database as part of the app? Are they micro services? This diagram is open to lots of interpretation. If this diagram had more text, we would at least know what these item were.
To look at this simply, imagine we are building a simple system consisting of a web app and a database. The word component means part of. For some people, the web app is a component for the entire system, but for other people, a logging component is a component of the web app. The same word is being used for different levels of abstraction.
A common discussion is the lack of a ubiquitous language between the developers and the business people, but we don’t even have that language among ourselves. UML tried to create this language, but it was too much. It attempted to create a standard notation and a standard level of abstraction but failed on both counts. I think that the industry needs a standard set of abstractions, and eventually create something like electrical engineering where there is a standard set of symbols to represent things, however we need to create the language first. With this, the language that we create needs to reflect the technology that we are using, merging the logical and developmental views back together creating real terminology that maps to real technology.
Container Model(13:49)
I don’t know how we could achieve an ubiquitous on a global scale, but within the boundaries of this presentation, I can show you some techniques. When I am discussing a software system, that software system is made up of containers where a container is simply something that stores data or runs code. To relate that to real terms, a container could be a web app, a Windows service, a database schema, etc. If you open a container, they are made of different components where components refer to something running inside a run-time environment. Essentially, it is a cohesive grouping of stuff with a clear interface when we are done. Since I mostly deal with Java and C#, components are built from classes. This creates a nice hierarchical tree structure to describe the static structure of a software system. If you’re using JavaScript, this makes no sense, so perhaps you use modules and objects or functions as components. The same can also be said with functional languages. Perhaps you are using a database technology, this can be adapted to components and stored procedures. You take the same hierarchical approach and map it to the same tech that you are using.
The ultimate goal is to create a single, simple static model of a software system on all levels; from viewing the system as a black box down to the code, with levels in between. Once you have defined language as we have, it makes creating diagrams really easy.

The C4 Model

The C4 model is a context diagram where you zoom in to see the containers, zoom in further to see the components, and even go down to code if you’d like, however I don’t usually do this especially if I’m trying to describe and existing code base quickly.
Tech Tribes
I created a site called Tech Tribes, which is just simple content aggregated for the local tech industry. Here is a context diagram for Tech Tribes, representing the system I built.
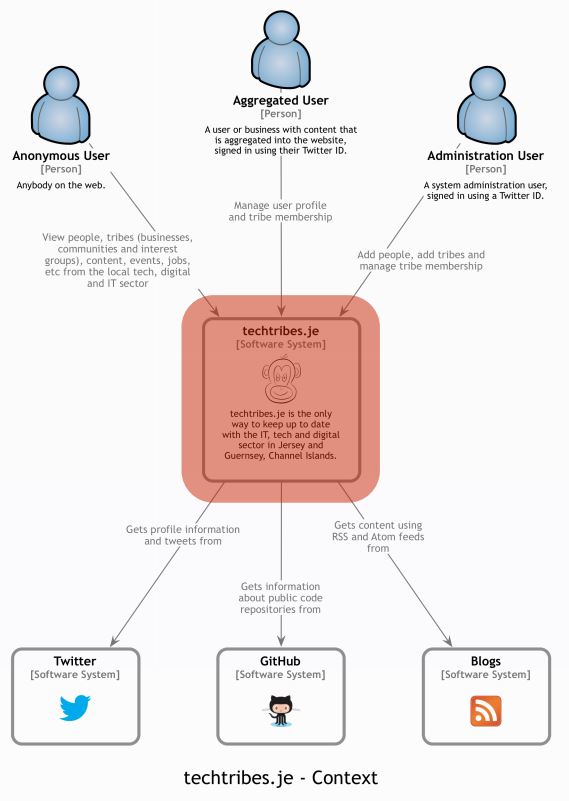
There are different types of users and different system dependencies. If this was an interactive Google Map, we could select and pinch to zoom in.
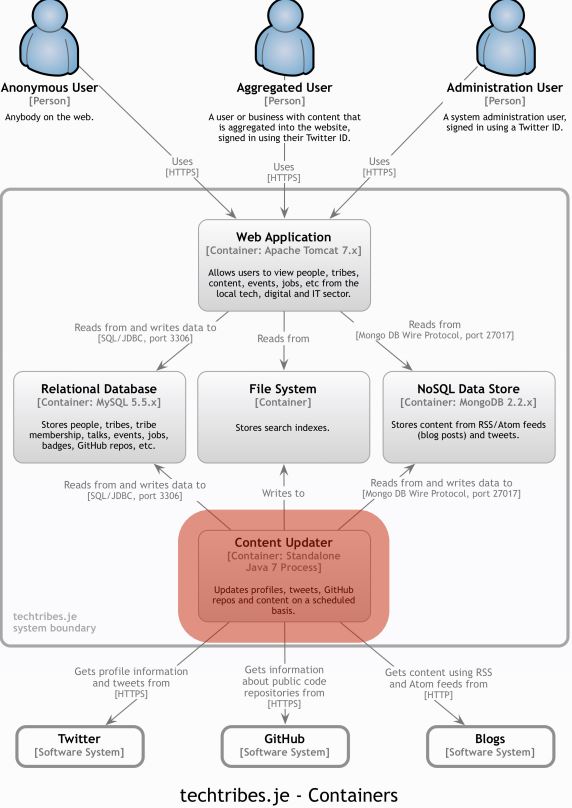
We see the containers inside the system boundary. If we select a container, we can pinch to zoom in, and show the components inside it, and so on and so forth.
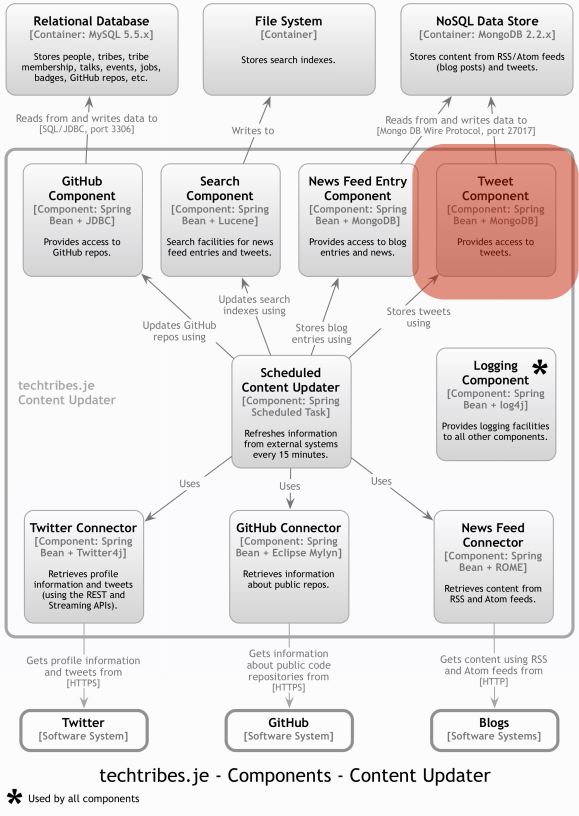
It is a simple hierarchical diagram that maps onto the language and ultimately we get to the code. Ideally there is a nice clean mapping between all of these layers, and this would actually represent what the code looks like.
Basically, diagrams are maps and you need different types of maps depending on how much information you have about what you want to learn about, or the audience you’re speaking to. For presenting to business and other non- technical people, a high level view works well. If you are showing your system to a developer, something low level would be good.
I don’t want you to take away any tips around notation. This is the notation that I use just because it’s very simple, and I tend to use things like color coding and shapes to supplement an existing diagram that already makes sense.
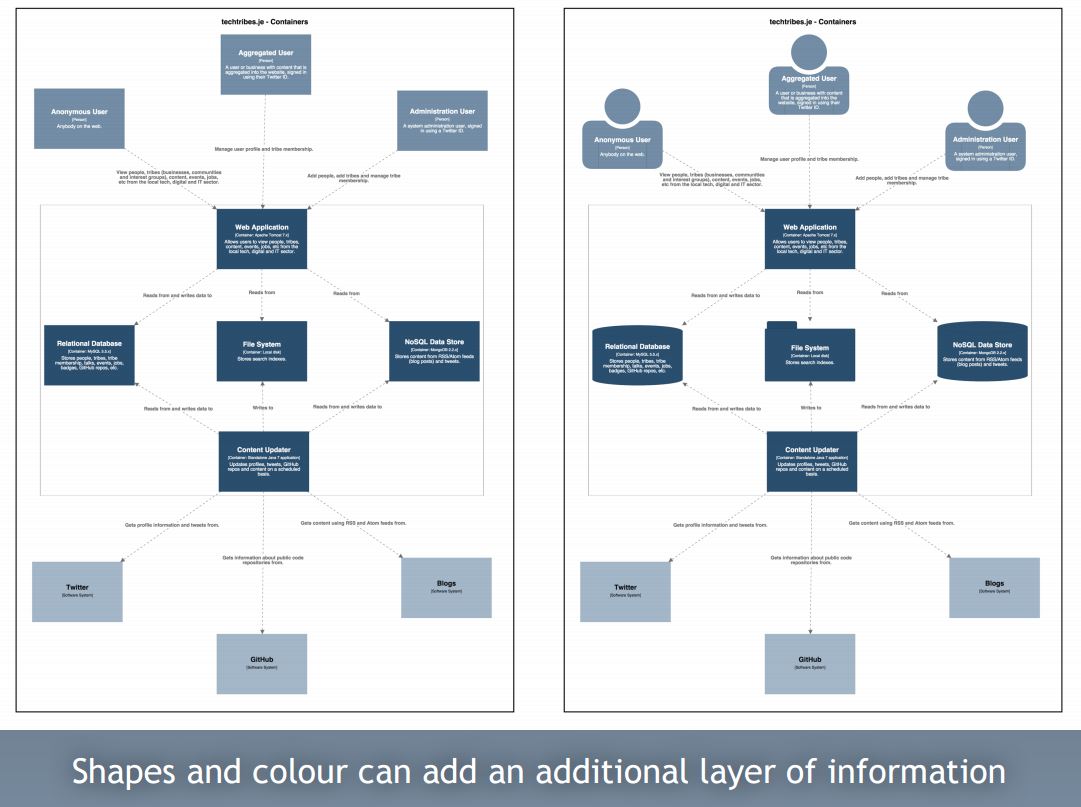
This is two representations of the same diagram. One has shapes and one doesn’t. Fundamentally, there is no additional information on the one with shapes, yet it is more appealing. It’s worth noting that there are a lot of other things worth considering when trying to describe your software architecture. Philippe Kruchten’s work as well as Eoin Wood’s book has a lot of good information regarding views and viewpoints.
Using the C4 model is not a design process, it is simply a set of diagrams that you can use during an up front design exercise or even to use retrospectively. If you have an existing code base with no documentation, this is a really good starting point.
What Tools Should I Use?(17:39)
A common question I receive is what tools I recommend, and don’t say Visio. This is because it’s just a set of boxes and lines, and is simply a general purpose diagramming tool not a modeling tool. If you look at the building industry, it doesn’t use Visio. They use three dimensional models of a building and surface different views from it. The irony of course is that we as developers build these tools for them, but don’t have any for ourselves.
Structurizr
I’m trying to solve lots of problems here and one of my approaches is a set of tooling called Structurizr. Structurizr is part SaaS product, part open source. In its very simplest form, you can write a simple, demanding specific language to create diagrams. Really this is an implementation of the C4 model with people, software systems, containers, and components I showed earlier. Structurizr is great for sketching up something small and simple, a single diagram at a time.
If I have an existing code base, why can’t I just auto-generate diagrams?
- You just get chaos.
Is that because your code base is chaos?
- Sometimes, but often not.
Often your diagram is just showing too much detail. Structurizr is all cloud based and many companies don’t want to send their entire architecture into the cloud, but many of my potential customers like Structurizr. In order for companies to still get the benefits I have recently built a simple on premise API because Structurizr is essentially a JavaScript app running in the browser. After installing the API, users can store their data locally. The API is only about 1,000 lines of code and here is the UML diagram for it.
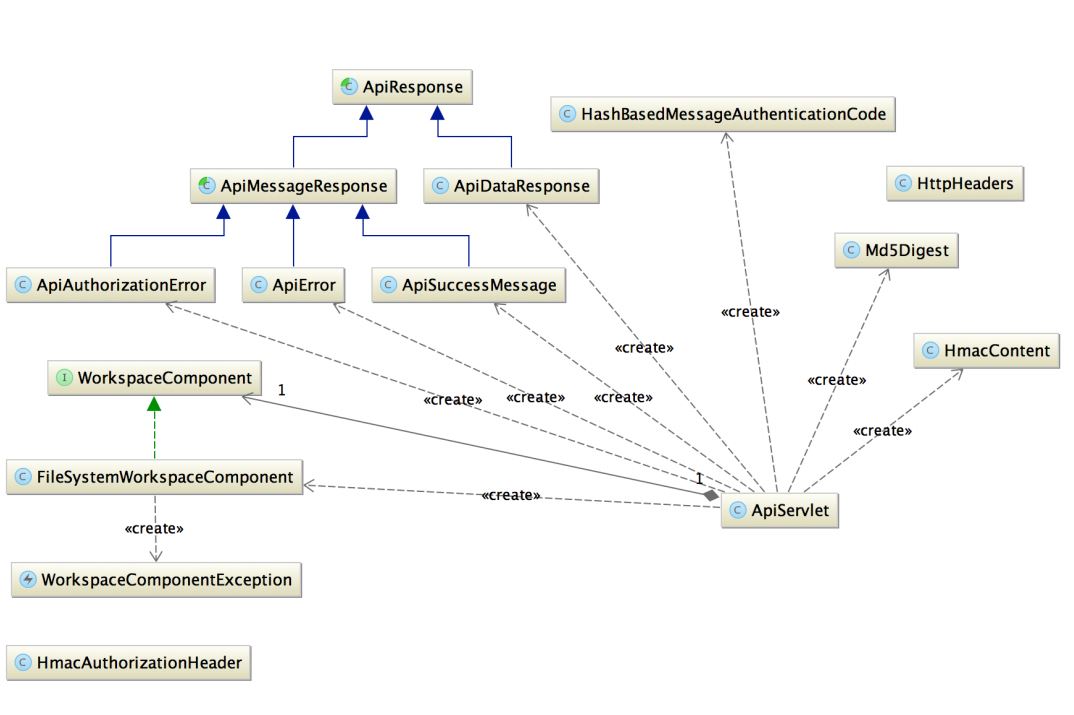
It’s not particularly useful is it? The diagram is showing us all of the code level elements and all of the relationships between them and it’s hard to pick out what the important parts of this code base are. Even with less than 1,00 lines the diagram is already useless, imagine if the code base was 100,000 or 1,000,000 lines; the diagram would become unreadable. This is simply because diagramming tools see code not components; they are unable to “zoom out” and show the user bigger abstractions, again creating a model-code gap.
Software engineers have been dealing with this problem for a long time. A paper was published in the 1990’s that noted that if you ask and engineer to draw a picture of their software, they will create a nice high level view. However if you reverse engineer a diagram from the code, the result is completely different. The reversed engineered diagram will be very accurate, but it’s not how the engineer thinks.
This age-old problem ties back to a simple question:
What is a component?
What is a component?(21:00)
If I want to draw a component diagram, I need to understand what a component is. Referring back to my class diagram, the “WorkspaceComponent” and “APIServlet” boxes are what I would consider the components of this API. There is a Java server that handles the API requests and a workspace component dealing with the the structure of the workspaces. You may have heard of “server-less,” this is “framework-less.” This is one of the simplest implementations you could possibly write. There are two major components and the rest of the code are parts of these components.
We have to assume that the code is the single point of truth; the code is the final embodiment of all the architectural ideas. If you were to give me your code base, could I generate a context diagram by looking for references to people and software systems in your code base? The answer is no, because we don’t have that information in our code base most of time. The same can be said for containers. There simply isn’t enough information in the code to be found by scraping data from the code base.
It is at the component level that I really want to generate diagrams automatically, because it is the most volatile and changes frequently. To help this, George Fairbanks says that we should adopt an architecturally-evident coding style.
Architecturally-evident Coding Style(22:29)
Architecturally-evident coding is embedding information into your code base so that your code base reflects your architectural ideas and intent. Concretely, it is simple things like using naming conventions. For example, if you have a logging component in your code base, make sure you have something called “logging component.” Another example could be namespacing or packaging convention, where there is one fold, one namespace or one package per box on the diagram. It could also be in machine readable metadata, annotating things that are important such as labeling components. By using this, we can then extract useful information form the code base and supplement that information where that information isn’t possible. Ideally, we as an industry should move away from drawing diagrams in programs like Visio.
Architecture Description Language(23:30)
An architecture description language, a term with most readers will probably be unfamiliar since it hasn’t entered the mainstream industry, is a textual description of something such as the static structure of a software system. There are many languages out there such as Darwin or Koala, however the syntaxes are horrible, essentially meaning developers have to learn another strange looking language in order to describe the piece of software that they are building. However, this is a fantastic concept, because we are no longer dealing with diagrams, but with text. As developers, we like text; we can “diff” text and have tooling to support text. We need to take all the concepts discussed above and create an architecture description language using general purpose code that we are using to build our systems.
This is what the other piece of Structurizr is. There are two Open Source libraries, which are a small implementation of the C4 elements discussed earlier. There are several classes in each library, one for Java and one for .NET, they let you create people, software systems, containers, and components and bind them together to describe your software architecture. This is how we would use this to describe my API from earlier:
// software systems and people
Person softwareDeveloper = model.addPerson(Location.Internal, "Software Developer", "A software developer.");
SoftwareSystem structurizr = model.addSoftwareSystem(Location.External, "Structurizr", "Visualise, document and explore your software architecture.");
SoftwareSystem structurizrApi = model.addSoftwareSystem(Location.Internal, "Structurizr API", "A simple implementation of the Structurizr API, which is designed to be run on-premises to support Structurizr's on-premises API feature.”);
softwareDeveloper.uses(structurizr, "Uses");
structurizr.uses(structurizrApi, "Gets and puts workspace data using”);
// system context view
SystemContextView contextView = views.createSystemContextView(structurizrApi, "Context", "The system context for the Structurizr API.");
contextView.addAllElements();
A software developer uses my Structurizr product, which uses the API to store information locally. This code reflects that model. We can then use that code to create a system context view by adding the appropriate things to the diagram. The resulting picture is a very simple way to describe high-level structures of a software system.

If we look at the container level, we have a similar picture. From a container perspective, all I have is an API server, which is a Java web app storing information on a file system. We write code to create a couple of containers and wind them together using method calls and create some diagrams.
// containers
Container apiApplication = structurizrApi.addContainer("API Application", "A simple implementation of the Structurizr API, which is designed to be run on-premises to support Structurizr's on-premises API feature.", "Java EE web application");
Container fileSystem = structurizrApi.addContainer("File System", "Stores workspace data.", "");
structurizr.uses(apiApplication, "Gets and puts workspaces using");
apiApplication.uses(fileSystem, "Stores information on");
// container view
ContainerView containerView = views.createContainerView(structurizrApi, "Containers", "The containers that make up the Structurizr API.");
containerView.addAllElements();
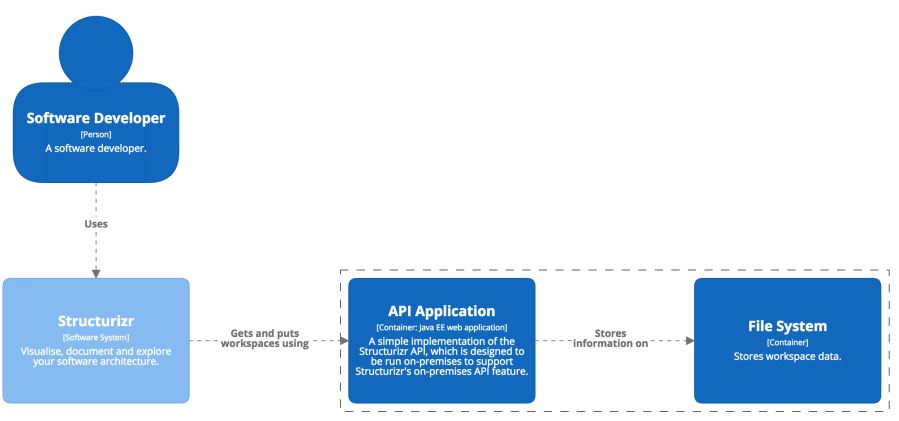
Essentially, you write code, and get pictures. This is very good for high-level stuff, however once you get down to components you don’t want to have to do this. Because of this, the Open Source Libraries have some component finders in them. The underlying question now shifts to “How do you find components.” The answer is simply that it is up to you, because every code base is different. If you follow an architecturally evident coding style and have a naming convention, you can find components based on this convention. If you use a framework like Spring for example, you can find Spring annotations and call them components etc.
This is the code I use to find the components in my API application.
// components
ComponentFinder componentFinder = new ComponentFinder(
apiApplication,
"com.structurizr.onpremisesapi",
new TypeBasedComponentFinderStrategy(
new NameSuffixTypeMatcher("Servlet", "", "Java Servlet")
),
new StructurizrAnnotationsComponentFinderStrategy(),
new SourceCodeComponentFinderStrategy(new File("../src"), 150));
componentFinder.findComponents();
structurizr.uses(
apiApplication.getComponentWithName("ApiServlet"), "Gets and puts workspaces using", "JSON/HTTPS");
// component view for the API Application container
ComponentView componentView = views.createComponentView(apiApplication, "Components", "The components within the API Server.");
componentView.addAllElements();
There are a few different strategies for finding components. I want to find items ending with the word “servlet,” and I want to find items that I’ve annotated with my own component annotation. After we find them, we wind them together. There is also some logic behind the scenes that finds the inter-component dependencies and creates a diagram.
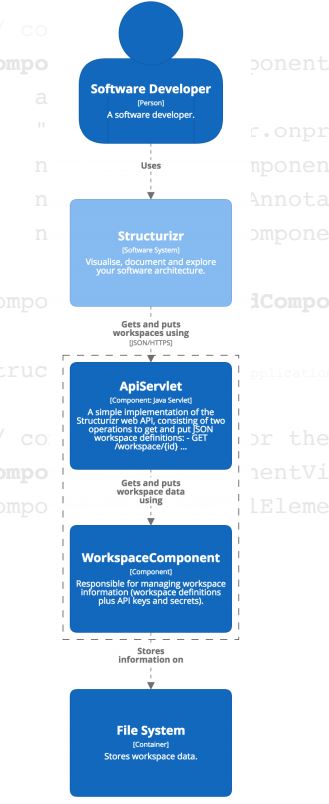
The API servlet and the the workspace component have both been found and a relationship between them has been identified. In order to get the additional text into the diagram additional metadata must be added to your code base.
Visualization as a Model(27:11)
This whole process is really about creating a model. I want developers to get away from using diagrams and move back towards using modeling as an approach for describing software. Once you have a model, you can do lots of interesting things like generating diagram keys automatically. We can move away from horrible notation we don’t understand. We can hyperlink the model to the code so that if you find the diagrams, you can click the components and go straight to GitHub, showing you the exact implementation of the item in the diagram.
Diagrams as maps
We want to look at diagrams as maps of our architecture, like our analogy showed earlier. One problem to this approach is scale. When I used this tooling we’ve developed on a web app I created this was the result:
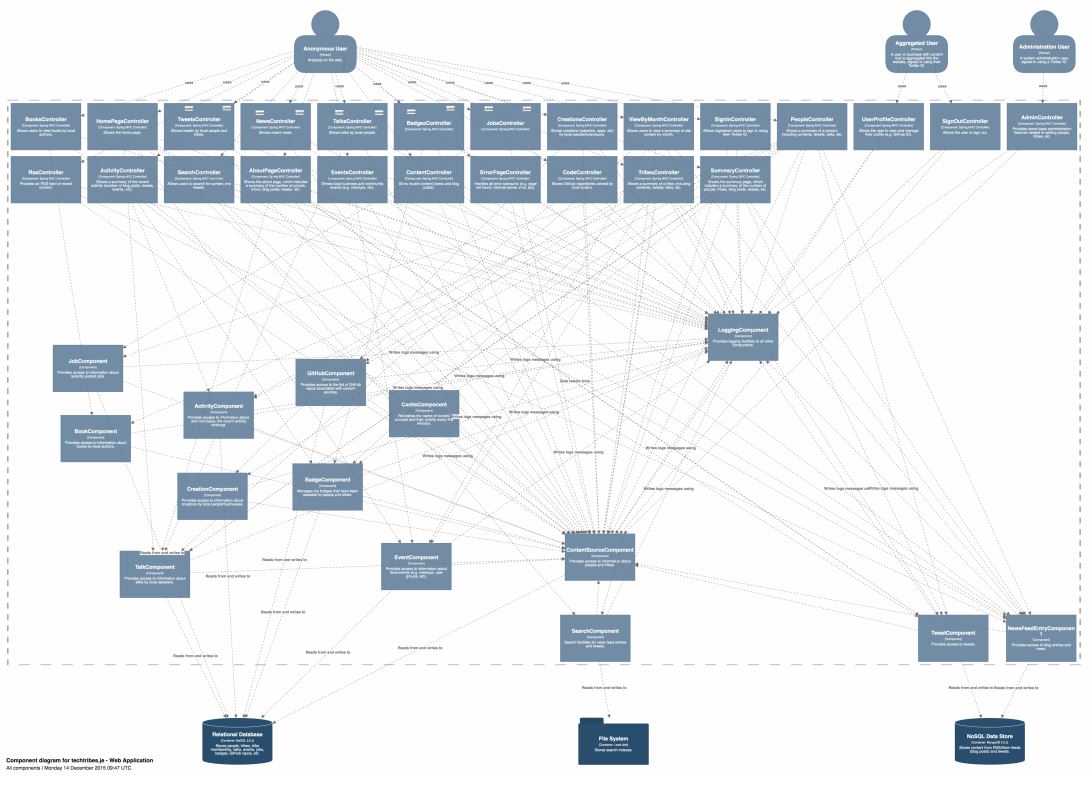
The diagram shows web app controllers and components, and the result is truly horrible. The code itself isn’t horrible, but yet the diagram is. Since this is a model however, you can not show everything, or you can only show the user a slice of the system. Perhaps a slice is starting from a web app controller or an entry point of your system, and show me the slice until your drop out the bottom of the app. You can essentially create a larger number of simpler pictures, allowing you to deal with scale. Once you have a model you can put it into lots of other types of tooling.
For example, if you’re a fan of Graphvis, the Java Open Source library is a Graphvis exporter that creates a DOC file that can be placed in Graphvis to auto-generate diagrams for you.
If you connect this whole idea to your build process, your documentation and your diagrams remain up to date as your code changes, which is ultimately the point I’m trying to make.
Documentation(29:13)
Many people are no longer documenting anything which probably sounds a bit extreme. We can thank the Agile Manifesto for the fall of documentation, because people misinterpret what it says about documentation.
If I dropped you into a project that is not familiar to you, and you’ve never seen the code base before, you would feel lost. You would have to start “zooming” around exploring to try to figure out where you are, which of course takes time. A you explore the code base, you’ll realize that the code doesn’t tell you everything you want to know especially with things like rational and intent. The reasoning behind decisions is often omitted from the code base. There is often lots of “tribal” knowledge, where teams have specialists and experts in particular parts of the base. This is all fine until one member gets run over by the proverbial London bus.
The Bus Factor
Imagine that you have a small team, and one member does get run over by a bus. Another member gets sabbatical for a year, and we have to fire someone else because they are useless. After all this, we have a much smaller team, and soon issues arise where a team member asks:
“You know that thing we have to run every week… … what is it..?”
Though this may seem like an extreme case, situations like this do happen. How do we fix our documentation problems? This is where the SAD comes into play. There are lot of templates out there for documentation, every consulting company I have ever worked at has created their own. These architecture documents usually include some insightful and interesting information such as how they arrived at their design, what some design decisions were, what the architecture is and how they look after it. In reality these documents tend to be horrible, with hundreds of pages, they’re out of date and just totally useless.
To fix this, naming turns out to be our friend. If we rename the document and call it a guidebook instead, all our problems go away. Like a tourist guidebook it includes maps to navigate the unfamiliar environment, itineraries, points of interest, the history, etc. For a software guidebook, maps are diagrams of the architecture, and show what the code looks like, what parts of the code base are important, and how the code base evolved to become what it is today. To make these documents more tolerable, my simple tip is to only include and describe what you can’t see from the code base. Essentially knock it up a level of abstraction and make things small. Avoid having hundreds of pages of things that simply become out of date and irrelevant. It is meant to be a living, breathing, evolving style of documents that changes with the code base, not an up front design. It is a supplementary piece of documentation that is meant to sit alongside the code base. It is a product related document, every software system should have a user guide essentially.
Documentation tooling
Many teams use Word or SharePoint. Lots of teams also use Conference. Another technique I’m seeing more teams use is MarkDown. They create documentation file and put them next to the source code in source code control. At build time the documentation performs a function such as generating HTML, uploading to websites and Wikis etc.
Something I want to do with Structurizr is to create a software architecture model that contains the model, the visualization, and the documentation. Here is some code I wrote to document my API application from earlier.
// documentation
File documentationRoot = new File(“.”);
Documentation documentation = workspace.getDocumentation();
documentation.addImages(documentationRoot);
documentation.add(structurizrApi, Type.Context, Format.Markdown, new File(documentationRoot, "context.md"));
documentation.add(structurizrApi, Type.Data, Format.Markdown, new File(documentationRoot, "data.md"));
documentation.add(structurizrApi, Type.Containers, Format.Markdown, new File(documentationRoot, "containers.md"));
documentation.add(apiApplication, Format.Markdown, new File(documentationRoot, "components.md"));
documentation.add(structurizrApi, Type.DevelopmentEnvironment, Format.Markdown, new File(documentationRoot, "development-environment.md"));
documentation.add(structurizrApi, Type.Deployment, Format.Markdown, new File(documentationRoot, "deployment.md"));
documentation.add(structurizrApi, Type.Usage, Format.Markdown, new File(documentationRoot, "usage.md"));
It is several simple MarkDown files which you upload as part of the model, and some documentation is generated for you. I want to keep everything in one place so you can embed diagrams into your documentation.
There are lots of other tools out there for living documentation that are Open Source and on GitHub that can be used for creating documentation from code. For example, there is a German team that has a software architecture document they call arc42. It is a lightweight and lean approach to documenting software systems, and is very similar to my own approach.
Documentation length
Many people ask me how long a documentation should be. Asking how many pages is the wrong thing to ask. What we are really looking for is a document that can be read in one to two hours over a coffee or two. The idea is to get a good jump-off point into the code so I can explore the code base in a much more structured way.
To aid again in visualization, once you have a model for your software, you can create new things like a JavaScript D3 visualization of the static elements, like a tree structure. Here is a sample application model from the Spring Team, called Spring Pet Clinic.
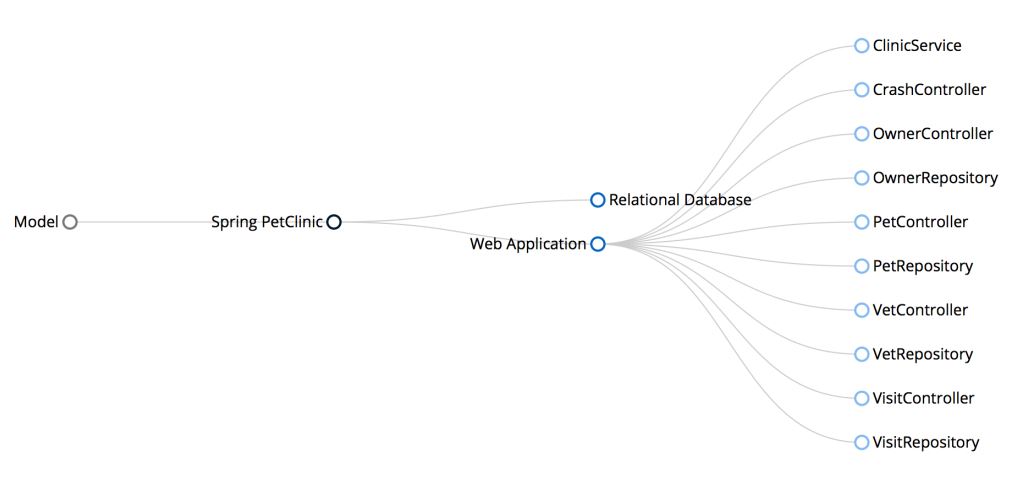
This is the software systems container’s and components. You can find all the interesting component dependencies, both incoming and outgoing. You could rate our components based on size and complexity. To reiterate, once you have a model you can do a lot of different things with it.
For example you can place your model into Neo4j and query it or cypher. The software architecture model is just a directive graph. There is another whole tooling called jQAssistant that takes your source code, allows you to set some rules and puts it into Neo behind the scenes. Another tooling set created by Empear, runs your source code repositories and does both static analysis and super imposes the human aspects over it. For example, it can find items that are always changed by two different teams, and ask why that is. We could have the component boundaries incorrect in this instance.
Summary(36:42)
There’s a virtual panel about software architecture documentation from 2009. It says that we should be able to see the architecture in the code, we should be able to embed this information into the code, and be able to get the documentation form the click of a button. It is really all about automating as much of the documentation as possible.
As far as visualization, we need to remember to think of diagrams as maps of our architecture. Treat your diagrams as a set of maps to your software architecture, that describe your code based on different levels of abstraction. Any document you create should describe what your code base doesn’t. Diagrams should be more than manually drawn boxes and lines, so we need to stop using tools like Visio to represent our systems.
In closing, whenever you’re describing software, make sure you have a ubiquitous language within your team to do so.
About the content
This talk was delivered live in October 2016 at goto; London. The video was transcribed by Realm and is published here with the permission of the conference organizers.


