

Brett gives an overview of neural networks, as well as how to build and train models using Tensorflow, Keras, and how to port those models to iOS.
Introduction
My name is Brett Koonce, and I’ll cover convolutional neural networks, Swift, and iOS 11, using some of the new APIs.
My background regarding neural networks is that I went to school to get a Master’s degree and I ended up in the Computer Vision Lab at the University of Missouri. This is how I learned much of what I will cover today.
Our goal here is to do image recognition on a mobile device. I’m going to do a quick background on Machine Learning and in neural networks. Then do a demo of how to combine Keras, TensorFlow, and CoreML which is a new part of iOS 11 to do image recognition on a device.
Machine Learning
Machine learning is where you take some input data, do some magic with math, and then you get the right answer. If not, you redo your models.
More specifically, we take an input, which can really just be thought of as a set of numbers. For example, a picture can be reduced to a very large collection of numbers, that will let us with work machine learning. Audio can be thought of same way - you can convert it into a histogram so that it basically means that audio is just a fancy form of a picture, which is just a fancy version of a bunch of numbers. And videos are like a sequence of pictures, which can also be reduced to numbers.
We have known data to work with. That is, we have data from cat pictures versus data from dog pictures; we just want to combine them together to perform some sort of magical black box. We input the cat pictures, and associate its data with a cat, and do the same with dog pictures. This will happen many times; this is called training a model.
At the end, you want to run it on unknown data, and hopefully, your unknown picture of a cat comes out as a cat. Much of this is dependent on the quality of our model (how accurate it is against our data), the size of the model, and how many CPU cycles it takes to actually run.
The first part of the demo we’re going to do here is the MNIST dataset. This is like the “Hello World” of Computer Vision. This is a dataset from the 70s and it consists of an array of pixels, 28 x 28.
There are several different ways to tackle the MNIST problem. With MNIST, we will build a neural network that will try to learn an activation function.
We will use Keras, which is a Python high-level library to build our network. Then we’ll use TensorFlow, which is a matrix math library from Google to do our actual calculations. Finally, we’ll deploy our model using CoreML.
I wrote this code a couple months ago, to sort of teach myself the new APIs after they came out at WWDC. You can download it off the internet if you want, but I’ll just walk you through it right now.
This is the basic script that has some Python imports and parameters.
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
from keras.utils import np_utils
This prepares our data set for doing our actual math.
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
This converts our categories into one-hot vectors.
# convert class vectors to binary class matrices
y_train = np_utils.to_categorical(y_train, num_classes)
y_test = np_utils.to_categorical(y_test, num_classes)
Finally, we just build a model.
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation='softmax'))
We use Keras to then train it on our input dataset.
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
history = model.fit(x_train, y_train,
batch_size=batch_size,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
Finally, we we save our MNIST model.
print("Saving mnist model")
import coremltools
coreml_model = coremltools.converters.keras.convert(model)
coreml_model.save("mnist_model.mlmodel")
Apple released a tool to convert Keras, and other models, to CoreML. It does nothing more than saving the model out as a file.
Our model now has a 98% accuracy on the MNSIT dataset, which is pretty good. We can export this, and it will provide us with a model that is 2.7 MB, which can be used to build a simple demo like this: demo project.
The following is the actual prediction/recognition portion:
let i = mnist_modelInput(input1: input_data)
guard let digit_prediction = try? model.prediction(input: i) else {
fatalError("something went wrong when doing the model prediction step")
}
let results = digit_prediction.output1
var maxIndex = -1
var maxPredection: NSNumber = -1
// @koonce: could make this slightly more elegant
for i in 0...9 {
let prediction = results[i]
if prediction.floatValue > maxPredection.floatValue {
maxPredection = prediction
maxIndex = i
}
}
Neural Networks
From here, we get into convolutional neural networks.
What is a convolution?
It’s simply a fancy word for matrix math. You can think of it as being nothing more than a, x, where x is a matrix plus b.
The two convolutions you should know about:
-
Striding. This basically takes an image and breaks it up into a bunch of smaller, little chunks. There’s some good documentation on the online course that you can read. The problem with striding is that it produces a lot of samples, so we want to squash it back down. Striding just simply takes this group of eight pixels and just goes through it and asks which is the biggest pixel and that’s what makes it a next generation.
-
VGGNet. This starts out with two, 3 x 3 strides, a Maxpool, two more 3 x 3 strides, another Maxpool, three, 3 x3 strides, Maxpool, three, 3 x 3 strides, Maxpools, and so on. For the final two layers for my demo, we did a 512 layer; the fully connected layer. The VGG uses just a larger one, which is just 4,000, or 4K. You have two of those and then the last one is instead of classifying the digits from one to 10, which would be 10 categories.
This picture here is sort of a visual of what’s going on with the data at each step. It’s sort of getting squashed down into something.
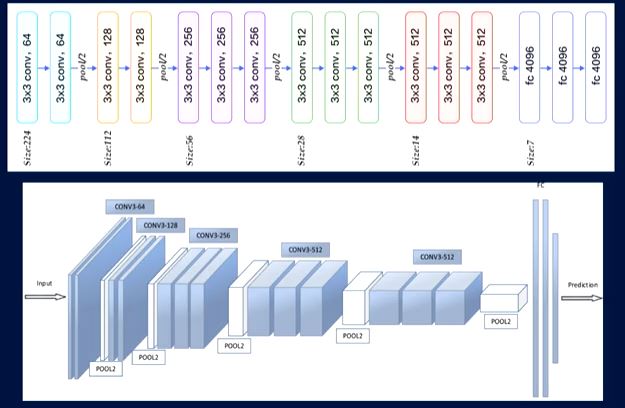
Finally, we have the two layers that do our neural network tricks. Then we perform our prediction.
We can run VGG on a phone by using an input image of a cat. It runs and it identifies that we have a cat picture. This took about three to five seconds to run. This is because the VGG network had to crunch through half a GB to make the prediction. Another reason is that it uses a lot of CPU cycles.
If you want to see the source code for this, my friend Matthijs wrote a whole set of these sort of things here.
Inception Network
Next, we will to go into the Inception network. The first important concept with Inception is this idea of parallel execution. We’re running convolutions, but we’re doing them in parallel. Basic Inception is four nodes working together. The problem with this is that it does actually work that way out of the box.
In order to make the Inception modules work, you have to add a one-by-one dimensionality reduction step. This is the website you can use to read a little more about that. The Inception architecture is basically a whole bunch of different nodes working together. We’re doing more math, but now we can have much fewer weights for our network. If VGG is about half a gigabyte worth of data, Inception is a little over a hundred. Here’s another good guide for what to do there.
Transfer Learning
Transfer learning is an important technique for you to understand. Take a model that’s been trained on one thing and modify it slightly to run on a different one - this will allow you to skip a week of doing GPU time.
Finally, we can take our model and optimize it for actual execution. We can take an Inception v3 graph model, and we can prune it. We can remove any extra nodes, and reduce it, which is just combining any nodes together so they don’t have to be calculated twice.
Most of the models are built in the double math, which is 64-bit. We can convert everything down to 16-bit integers. For example, an Inception model is 100 megabytes, and we can reduce it to 25 megabytes just by changing the precision of our math.
Finally, we can align the data by doing a memory map of the data to make sure it’s fitting on the device in such a way that it runs optimally at run time.
Residual Networks
The next concept is residual networks. This concept is from a paper that came out of Microsoft last year. The basic idea is to skip layers; we can have layers that bypass the steps as they go down.
The first model is a VGG-19, which is the cousin of the VGG-16 that we saw earlier. If you’re computing a graph and you get down to the last step, you’re throwing away all the data that came before. Residual networks make the final score actually be a combination of everything that came before. This allows you to do much deeper training, and as a result, people have built 200 and 1,000 layer networks with this methodology.
Finally, what I’m excited about is called MobileNets. It’s a paper released by Google in April. It makes heavy use of the concept called Depthwise Separable Convolutions. It’s a relative of the one-by-one dimensionality reduction part of Inception. This was announced a few months ago.
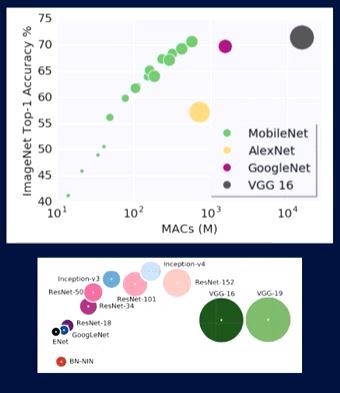
If you look at our graph, the large gray blob is our VGG-16 model from before. These little networks are all the MobileNets. You can think of this as the horizontal axis being how many CPU cycles it takes to make you run your model. The other axis is just your quality or your accuracy on these various image recognition graphs. The size of the circle itself is represented where the smaller the circle, the smaller the actual model is.
Questions
If I want to build an iOS app that can identify objects from the live camera feed, should I do all my optimizing in the Python code before I export the model?
Yeah, the model itself would be the optimization.
Can you run this on iOS 10? Or is it iOS 11 only?
The Inception demos can all be run on iOS 10 or before. The ones that are using CoreML, will require iOS 11.
About the content
This content has been published here with the express permission of the author.


