

Ever wondered what your Android sees? Buckle up and join me on the journey to explore computer vision on mobile; explore different examples and walk through the basics of the available vision APIs.
Introduction
My name is Adrian, and I would like to talk a little about machine learning and computer vision. What is machine learning?
Suppose you have to develop an app that takes a picture, and it has to check if the picture is of a bird. Machine learning is not a new problem, it’s a subset of artificial intelligence and AI has been around since maybe mid 50’s, only it’s been a struggle for a proper implementation.
Examples
The simplest problem that we can tackle using vision algorithms is classification, such as if someone is a dog or a cat. Other implementations of machine learning include gaming: Deep Blue playing chess; AlphaGo playing Go.
-
Google Play Music, an algorithm called wide and deep approach is used for artist recommendations.
-
Smart replies in the inbox - they are using a network with clustering in order to identify which is one of the most common ways that we used to reply an email.
-
Parsey McParseface, is Google’s natural language processing tool. It comes with a model, open source in TensorFlow.
-
Style transfer - we give an input and the artificial intelligence will generate an output.
-
Rainforest learning. This is similar to AlphaGo. In this case, the AI is not taught with labels, instead of being taught with rewards and punishments.
The Simple Explanation
“As soon as it works, no one calls it AI anymore”
This is a quote from John McCarthy and it makes a lot of sense - a lot of people are talking about AI and at some point in history, automatic garbage collection was considered AI. Now, it’s considered just another algorithm.
Many people say they are doing AI, but are merely implementing a lot of chained if statements. I would like to show the difference between doing if statements and using a neural network and machine learning algorithms.
Can machines actually learn?
The answer is yes, with lots of data.
At the moment, Machine learning is only solving specific problems and is not considered strong AI. Machine learning can’t solve new problems but can provide some insights to assist in solving them. Suppose we want to figure out how much property is worth around an area (Machine Learning is Fun).
It’s possible to figure out this value by using the number of bedrooms, the size, and the neighborhood to determine the sale price of a house. This is the simplest to solve the problem, and it uses three variables.
This can be simplified by figuring out how important each one of these variables is on the final result and assign a volume for that importance. This is called a weight - and it will provide us with the final equation.
Figuring out the value of the weight is a linear regression. Once we have the values, it’s easy to predict what’s going to be the sales price. This is called supervised learning because we’re given data with labels and we’re going to focus on that in this presentation.
On the other hand, range forcement learning, is when the values are not present, and we give the computer incentives and punishments.
The Calculation
We initialize the weights because we don’t know how much importance each one of the variables has. Let each one be multiplied by one at first, then calculate the error. If we calculated the sales price of a house to be $250,000 and it was $200,000, the difference is the error. I square it and get an average of the errors.
Trying these new values can be done just in a random way. A derivative is helpful in this case: if we get to build a graph using the variables, it will look like a bowl.
This is called a gradient descent algorithm - by iterating through it, we’ll get the minimum values.
We can do several different calculations, different approaches and we’re going to end up with several possible price estimates and eventually, we would like to join them all in one final result called a neural network:
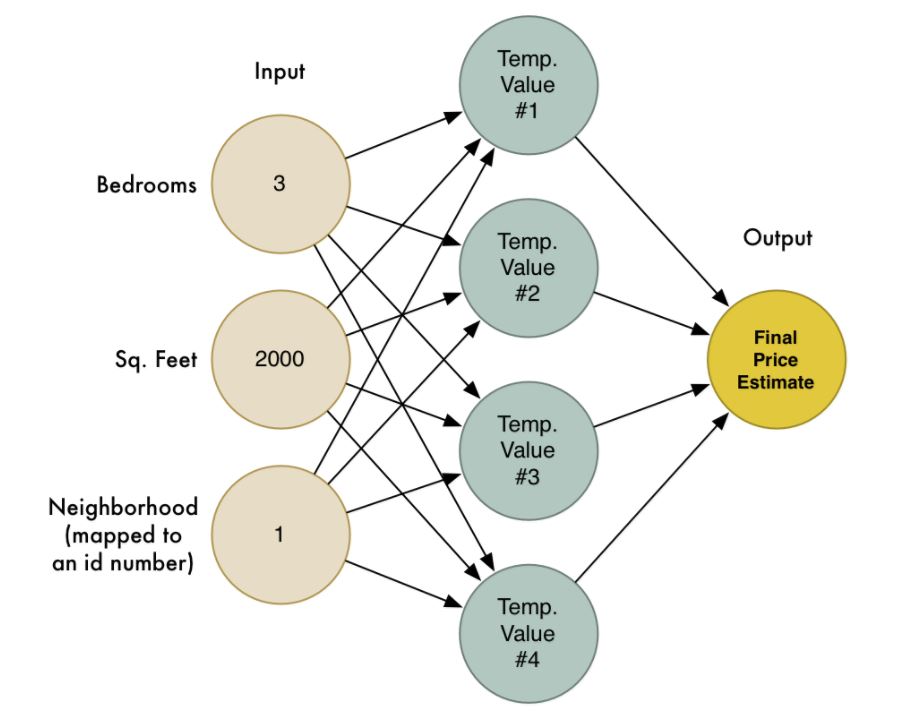
A neural network is based on how people think. Our brain works with neurons and electrical impulses that activate those neurons. We are building neurons as units of processing that have math equations.
There is an infographic of all the neural networks. The simplest one is called a Perceptron. It could be as simple as an AND or XOR logical operation.
Three Approaches To Machine Learning
I would like to mention three different ways to approach to machine learning.
Via API
I would like to show a couple of examples about how to use machine learning using an API.
I’ll show some examples using Google Cloud Vision, Cognitive Services for Microsoft and IBM Watson. In all the cases, an image is uploaded to the API from the gallery or camera.
In Google’s case, we’ll work with a custom object called batchAnnotateImageRequest. We need to provide a match using base-64 encoding and then, in order to do the request, we need to specify what are we looking for.
BatchAnnotateImagesRequest batchAnnotateImagesRequest
= BatchAnnotateImagesRequest();
batchAnnotateImagesRequest.setRequests(new ArrayList<AnnotateImageRequest>()
{{
AnnotateImageRequest annotateImageRequest = new AnnotateImageRequest();
...
byte[] imageBytes = byteArrayOutputStream.toByteArray();
base64EncodedImage.encodeContent(imageBytes);
annotateImageRequest.setImage(base64EncodedImage);
...
I would like to detect some faces and I would like to detect some labels. We add those to the request. Build the vision request and eventually execute it.
{{
...
annotateImageRequest.setFeatures(new ArrayList<Feature>() {{
Feature labelDetection = new Feature();
labelDetection.setType(String.valueOf(Detection.LABEL_DETECTION));
labelDetection.setMaxResults(MAX_LABELS);
add(labelDetection);
Feature faceDetection = new Feature();
faceDetection.setType(String.valueOf(Detection.FACE_DETECTION));
faceDetection.setMaxResults(MAX_FACES);
add(faceDetection);
}});
add(annotationImageRequest);
}});
There’s nothing weird happening here. It’s like a request to any other API. We’re specifying the picture that we would like for the API to analyze.
Vision.Builder builder Vision.Builder(httpTransport, jsonFactory, null);
builder.setVisionRequestInitializer(new VisionRequestInitializer(APIKey));
Vision vision = builder.build();
Vision.Images.Annotate annotateRequest =
vision.images().annotate(batchAnnotateImagesRequest);
annotateRequest.setDisableGZipContent(true);
response = annotateRequest.execute();
Microsoft Cognitive Services
Microsoft Cognitive Services identifies or tries to guess the age of the person that is in the picture.
String[] features = {"ImageType", "Color", "Faces", "Adult", "Categories", "Tags", "Description"};
String[] details = {};
ByteArrayOutputStream output = new ByteArrayOutputStream();
bitMap.compress(Bitmap.compressFormat.JPEG, 100, output);
ByteArrayInputStream inputStream = new
ByteArrayInputStream(output.toByteArray());
AnalysisResult v = this.client.analyzeImage(inputStream, features, details);
Similar as before, we need to initialize the call to the API here where it’s specifying on the first line faces, adult content, categories, tags, and description. It’s going to try to guess the description of like the whole image.
We’re graphing the captions. If you look here, it will show several things.
if (response.description != null) {
if (response.description.tags!= null) {
message += "Description tags\n" +
response.description.tags.toString() + "\n";
}
List<Caption> captions = response.description.captions;
if (captions != null) {
message += "Captions\n";
for (Caption caption : captions) {
message += String.format(Locale.US, "%.3f: %s\n",
caption.confidence,
caption.text);
}
}
}
By showing it a picture, it will find a table, indoor, bottle, desk, and cell phone, for example. Using the gallery for the face, it’s something similar. We’re just graphing the points in order to draw it on the canvas.
if(response.faces != null && !response.faces.isEmpty()) {
messages += "Faces\n";
for (Face face : response.faces) {
message += String.format(Locale.US, "%d: Age\n",
face.age);
message += String.format(Locale.US, "%s: Gender\n",
face.gender);
RectF faceRectangle = new
RectF(face.faceRectangle.left,
face.faceRectangle.top,
face.faceRectangle.left + face.faceRectangle.width,
face.faceRectangle.top + face.faceRectangle.height);
facesRectangles.add(faceRectangle);
}
}
The description is not entirely accurate, but it’s sure there is a person in the picture.
Watson
With Watson, you can also train a model, giving you a lot more power and reconfigurability.
ClassifyImagesOptions classificationOptions = new ClassifyImagesOptions
.Builder()
.images(file)
.build();
VisualClassification classificationResult = service
.classify(classificationOptions)
.execute();
VisualRecognitionOptions recognitionOptions = new VisualRecognitionOptions
.Builder()
.images(file)
.build();
DetectedFaces recognitionResults = service
.detectFaces(recognitionOptions)
.execute();
Mobile Vision
Mobile Vision is a limited version of Cloud Vision, but it runs locally, relying on Google Play services. It works for image recognition, OCR, characters, and barcodes.
I built a simple app similar to SnapChat filters. Here, I draw on the screen when the app detects a face.
class CustomFaceTracker extends Tracker<Face> {
private ImageOverlay imageOverlay;
public CustomFaceTracker(ImageOverlay imageOverlay) { this.imageOverlay = imageOverlay; }
@Override
public void onNewItem(int id, Face face) {}
@Override
public void onUpdate(FaceDetector.Detections<Face> detectionResults , Face face) {
imageOverlay.update(face.getPosition(), face.getHeight());
}
@Override
public void onMissing(FaceDetector.Detections<Face> detectionResults) {
imageOverlay.clear();
}
@Override
public void onDone() {
imageOverlay.clear();
}
}
We’ll need to initialize face tracker.
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
if ((previewWidth != 0) && (previewHeight != 0)) {
widthScale = (float) canvas.getWidth() / (float) previewWidth;
heightScale = (float) canvas.getHeight() / (float) previewHeight;
}
if (drawing) {
Bitmap scaledBitmap = Bitmap.createScaledBitmap(mBitmap,
Math.round(scaleX(faceWidth)),
Math.round(scaleY(faceHeight)), true);
canvas.drawBitmap(scaledBitmap,
(canvas.getWidth() - scaleX(facePosition.x + faceWidth)),
scaleY(facePosition.y), paint);
} else {
canvas.drawColor(0, PorterDuff.Mode.CLEAR);
}
}
What I’ve done is build a detector to detect faces/landmarks. I’m using fast mode to keep it optimized, and setting a minimum size for the face.
Training Our Own Models With TensorFlow
With TensorFlow, we can train our own models or retrain existing models. In this example, we will retrain a model called Inception. That model is based on ImageNet from Google.
To retrain, we will be using Docker to graph TensorFlow. There are some cases in which the training data is really good, but it’s not useful for real world problems - this is called overfeeding.
We are working with a network, so there is a graph, labels, and the directory. If we just generate this new graph, it’s not going to work immediately on mobile. To do this, build some TensorFlow tools to optimize.
On my slides, there is an example video of me testing the model.
About the content
This talk was delivered live in April 2017 at Droidcon Boston. The video was recorded, produced, and transcribed by Realm, and is published here with the permission of the conference organizers.


