

概述
今天我们谈论的话题是”让您的 iOS 应用加入到机器学习的浪潮中”。机器学习在 WWDC 2017 中的确是一个非常热门的话题,因为这个功能的推出出乎了大家的意料——我以为只会有几个小更新而已,不过我相信诸位在这一周内,已经听过很多关于机器学习相关的话题了。
我是 SoundCloud 公司的一名 iOS 开发人员,公司位于柏林,我曾在大学中学习过数学专业和计算机专业。我在学校中接触过机器学习,但是所学的内容并不具备太大的实用性,因此当我最近决定重回机器学习领域的时候,我发现我不得不将几乎所有的内容重新学习一遍。
议程
- 为什么要在应用中使用机器学习,以及什么时候才是正确的使用时机:我会用一个关于机器学习基础的速成课程 (crash course),以确保在场的所有人都能够将所使用的术语给统一。
- 我们将探索 Apple 所提供的相关 API。这已经通过 WWDC 2017 API 进行了更新。
- 作为开发人员,在使用这些 API 时候的常用工作流程。
- 使用基于 Python 的开源工具 Keras 自行创建一个机器学习模型。
- 我们将讨论更深层次的工具,由于这个内容十分宽泛,因此您可以自行去深入研究机器学习。
机器学习的相关定义
所以什么是机器学习呢?
大概所有人都知道机器学习的概念,但是为了以防万一,简单而言,机器学习可以让机器能够像婴儿一样去学习。如果您想要让机器知道您想要做什么的话,机器只能根据不同的建模方法来推断这一点。AI 创始者 Arthur Samuel 将机器学习定义为一种研究领域,能够让计算机在没有明确编程的情况下自我学习。

一个很简单的机器学习领域便是图像分类了。这里有一张小狗的照片,它是 SoundCloud 办公室的一员,如果我们将这张照片传递给机器学习模型,我们会希望机器学习模型能够将这个照片分类为狗,而不是猫、乌龟或者其他乱七八糟的东西。其他常见的领域包括了面部检测,这个已经由 iPhone 中的”照片“应用所实现;另一个例子则是音乐推荐,或者任意类型的推荐系统。手写检测略微有些困难,但是我们仍然可以使用机器学习来识别它。
Apple 在 Siri、相机和 QuickType 当中使用了这些技术:图像识别、照片中的人脸检测,此外 SoundCloud 会基于用户的音乐偏好来为其创建电台。此外还有很多关于机器学习领域的例子,但是这些例子只是最基础的应用而已。
为什么要使用机器学习
机器学习能够给用户带来更加丰富的体验。这也是大家使用机器学习的主要原因之一。此外,个性化、可识别性以及语义分提取也能够极大地丰富您的应用体验。用户经常会陷入这样的窘境:他们很难描述他们切实所想要的功能,但是在看到这个功能的时候才恍然大悟。或许他们无法用准确的词汇来描述一辆非常漂亮的自行车,但是当用户看到比赛用自行车的时候才意识到这就是他们所想要的,因为它有很多很明显的特征。回想比识别要更加困难。
借助 Apple 的机器学习 API,我们将能够在设备上进行预测,随后我们将会介绍这一点。此时您就必须要有一个预先训练过的模型,然后使用该模型来预测输出。
但是我们为什么要在设备上来进行预测,而不是在云中执行此操作呢,例如说使用 Amazon 或者 Microsoft 的一些开箱即用的解决方案?几乎每个大公司都有类似的云服务,也就是机器学习服务。为什么我们想要自行创建模型,然后将模型放在设备上,并在设备上执行预测呢?
Apple 在 Platform State of the Union 以及其他相关的机器学习 Session 中解释了这一点,只要您去过或者看过任一一个 Session 的话,那么就知道原因了。之所以要这样做,其主要原因是可以发挥 Apple 产品的优势,特别是保证用户数据的隐私。如果您在设备上使用了机器学习模型,那么数据将停留在设备当中,您可以确保用户的数据不会被窃取。
第二个原因是设备的计算能力是完全免费的。如果您要使用诸如 Amazon 之类的某个云服务,那么您将不得不为此而付费,而如果您是通过设备来进行预测的话,那么就可以利用现成的免费计算力。这个计算力将始终可用。如果您的模型存放在本机的话,那么就不会涉及到任何的网络访问,因此即便设备是离线状态,您也可以保证预测将始终可用,因为预测操作是不需要网络就可以进行的。
最后一个原因,是因为 Apple 的机器学习专门针对设备性能进行了优化。Apple 在这一点做得很好,他们展示了相关的性能数据,根据模型类型和您的目的就可以决定是使用 CPU 还是 GPU。我们可以从近年来 GPU 性能的大幅提升中受益匪浅。
对了还有一点,同时也是非常重要的一点,这样做能够最大限度地减少内存占用和功耗。Apple 对这些操作已经进行了大量的优化,如果您尝试在设备上进行预测,以前是会出现很多问题的,不过现在通过使用新的 API,由于 Apple 已经进行了大量的优化,那么现在内存占用和功耗就不再是问题了。
将机器学习功能添加到应用中
如果您想将机器学习功能添加到您的应用当中的话,那么您需要一个理由,为什么您需要这样做,以及该如何正确地添加这个功能。
我建议您去确定应用的关键绩效指标 (Key Performance Indicator, KPI)。例如,在 SoundCloud 中,如果我们需要添加这些机器学习库的话,或许我们的 KPI 是普通用户每天在听歌上所花费的时间,那么我们将制定相关假设,关于机器学习是如何影响 KPI 的,然后进行相关的实验,测量前后的效果。我们需要验证机器学习所带来的好处是有益的,如果没有的话,就进行重新组合,尝试不同的机器学习技术,或者采用别的方法。
机器学习原理速成课
模型是什么?模型只是一个基于给定的输入来输出预测值的系统。这个系统十分依赖数学知识,所以这是一个非常庞大的抽象概念,但是如果您只是使用 Apple 的 API 的话,您完全不必去担心这些底层细节。这就是机器学习的魅力所在。
神经网络基础
机器学习方案有各种各样的类型,但是您最常听到的便是神经网络了。神经网络的目标就是让机器像大脑一样可以自我学习。它是一个由神经元(结点)组成的高度互联系统,并且具备动态性,所以它能够处理输入,并根据输入来更新其状态。
神经网络的形状和大小各异。实际上有一个”神经网络大观园”,您可以在其中看到所有的拓扑结构。再次强调一点,您不必去担心底层的实现细节,我们可以将其抽象出来,但是如果您想要深入了解的话,就会发现神经网络的确是一个很赞的算法。
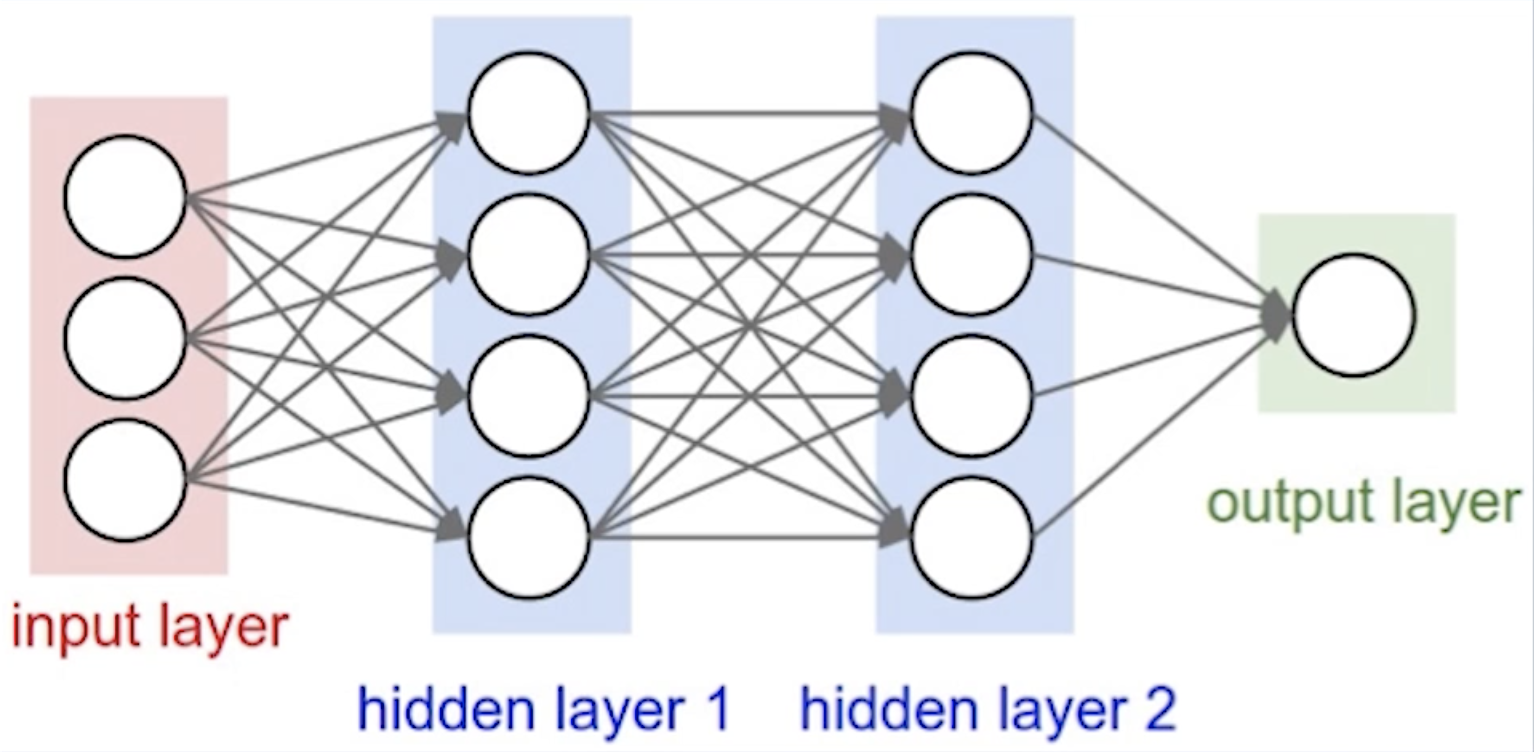
那么神经网络是如何工作的呢?从高层次来看,它是什么样子的呢?如上图左侧所示,我们给定一组输入,然后将输入传递到神经网络当中,然后它将会通过一系列的层。当输入通过这些层的时候,就会基于节点上所应用的权重产生相应的输出,并且每个层都会对数据做出相应的变换操作。随着时间的推移,从而创建出网络拓扑、激励函数以及其他的属性。这些属性决定了神经网络的运作方式。您最终会得到一个输出,您可以将神经网络产生的输出与预期输出进行比较,以便在将来对模型进行改进。
训练模型
为了改进我们的模型,我们需要对神经网络进行训练,我的意思是,我们的神经网络将多次循环遍历训练数据集中的输入,随着时间的推移,神经网络将会开始演进,不同的突触开始增长,这意味着这个神经网络将越来越准确,这个操作与改变神经网络方程权重所对应。一旦模型训练完毕,您就构建出了一个描述模型的方程,然后您就可以用它来执行预测。这可以用机器学习模型格式来描述,这样您就可以在应用中使用了。
训练完模型之后,当您有新的数据时,您就可以对其执行模型,这就称之为推断。这样就会得到一个预测输出。那么这些操作都是在哪里进行的呢?Apple 的 API 只允许在设备上进行推断。因此您需要有一个预先训练好的模型来执行预测。
选择一个预训练模型
那么我们该从哪儿去获取模型呢?训练模型需要很大的资金投入。如果您想要自行训练并创建模型的话,那么您将为此承担很多的服务器费用。
Apple 提供了四个预训练模型。这些模型在识别大多数日常图像方面做得很不错,因此它可以识别咖啡、电脑、手机、话筒等等。这可用于很多例子当中,所以我建议大家从这些预训练模型当中开始。预训练模型有四种,它们分别适用于不同大小的用例。
第二种选择就是使用开源产品。Keras 是一个开源的训练工具,我们之后将会介绍它。它也包含了几种预训练模型,您也可以借此来开始。
Apple 机器学习 API
在 iOS 11 中,Apple 给了我们很多关于 iOS 机器学习的便利。在顶层级别,我们可以使用三种不同的框架,可以借此来帮助我们解决一些机器学习的问题:
- Vision 框架
- 自然语言处理框架
- GameplayKit 框架
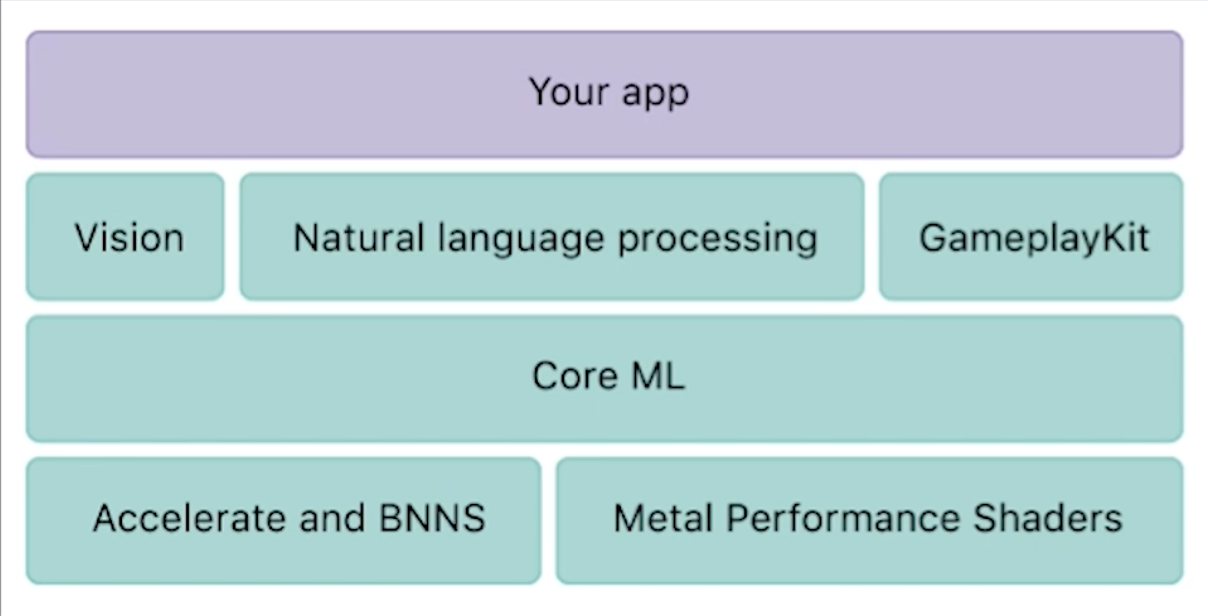
Vision 框架为您的计算机提供了视觉实用程序,以便能够将标准计算机视觉相关的功能添加到您的应用中。例如,框架中有脸部追踪、人脸检测、文本检测、形状检测、条形码检测以及其他相关的东西。
自然语言处理可用于从任何类型的文本中提取文本含义,这个功能是包含在 Foundation 框架中的。使用这种功能的例子包括了语言识别、部分语音识别、人名识别或者其他文本类型的分解并尝试提取其中的含义。
GameplayKit 我不是很了解,但是它使用了一种名为学习决策树 (learn decision tree) 的机制。
下一层则是 Core ML。您可以直接在应用中使用这三种高级别的 API,也可以直接使用 Core ML,将预训练模型集成进去,这个模型可以是由 Apple 提供,也可以是从开源项目中导入,也可以是自行创建的。Apple 为我们提供了一个很好用的统一 API,从而能够借助机器学习模型格式来使用任意类型的模型,您只需要编写几行代码就可以完成很酷炫的操作。
您也可以更深入底层,也就是可以在 iOS 11 之前做到机器学习,那就是直接使用 Metal Performance Shader,这是 Metal 框架中重度使用 GPU 的部分工具。您可以直接使用,但是这样的话您就不得不自行处理很多事务——但是您可以直接进行控制,它能够直接对 GPU 进行操作。Core ML 会将模型进行优化,并决定是使用 CPU 还是 GPU 来执行预测,使得您可以避免去和那些抽象概念打交道。您也可以使用 Accelerate 或者 BNNS。
集成 Core ML
在使用机器学习的时候,大部分 API 都是以 CPU 为中心的。我们将主要关注 Core ML 以及其工作流程是什么样的,然后学习如何导入模型,以及您可以借助 Core ML 实现哪些类型的操作。
Core ML 中提供了许多不同类型的机器学习方法。其中有迷你神经网络、组合树、支持向量机和广义线性模型。Core ML 提供给我们的方法基本涵盖了绝大多数机器学习技术。
那么这个工作流是什么样的呢?您该如何使用这个模型来改进应用呢?
集成 Core ML 是非常简单的。首先,您可以将文档中 Apple 提供的四种机器学习模型中的某一个,导入到 Xcode 当中。Xcode 将会直接用 Swift 生成一个具备该模型名称的类。他们在 WWDC 中使用的一个例子就是这个 MarsHabitatPricer() 机器学习模型了,它基本上是一个关于地价的预测模型,只是预测的是火星上的地价。
您可以使用 MarsHabitatPricer() 来初始化该模型——这个操作非常简单。然后,您将数据输入到模型当中,并进行预测。为了使用模型进行预测,您只需要使用您所创建的模型,然后基于您拥有的输入来调用它的预测方法即可。
然后万事大吉!(之后就可以编译运行并测试,并且确保它能够按照预期工作即可……)
第三方模型
但是如果您想要自定义机器学习模型该怎么办呢?什么时候需要自行构建一个模型呢?当您看过所有 Apple 提供的模型,查看他们关于可以使用什么的描述。当所有模型都无法为您的应用带来价值的时候,这很可能就是需要使用自定义模型的时候了。
第一个选项就是使用 Places205-GoogleNet 图像数据集模型。它可以检测 205 个类别的图像场景,比如说它可以检测您是否正在机场里面。它会给出高度的描述信息,表示您现在正在机场,而不是寻找可能会出现在图片前景当中的飞机。
还有另外三种不同的数据模型:ResNet50、Inception V3 和 VGG16,用于检测照片中的焦点对象,因此它会将背景给忽略掉,并且可以识别大约 1,000 个类别。每一个模型都包含有一定数量的类别,并且类别的数量也不一而足。所以这就是您需要考虑的问题了,因为这些模型是非常庞大的。虽然 VGG16 模型被广泛应用于跨学科的机器学习,但是将其集成到应用当中并不是很实用,因为机器学习模型需要在构建的时候能够正确加载,并且这很可能会意味着占用了大量的内存,甚至可能会导致内存消耗殆尽。
开源模型
我会推荐有这部分需求的人去 Keras 的 Github 页面。Apple 发布了一个 Core ML 模型迁移工具。大多数机器学习社区都是以 Python 为中心的,尽管我们当中绝大部分人都不是 Python 开发者,但是 Python 无疑有大量的文档和资源,因此您需要使用这个模型迁移工具,这样才能够在应用中使用它。我不认为这应该被视为障碍——我们应该积极体谅这一点,因为社区中已经有很多现成的资源。为了使用这个工具,您不需要配置 Python 环境,所以这里我会简单提及一下。基本上您只需要运行 pip install -U coremltools 就行。coremltools 是 Apple 所提供的工具。
pip 是 Python 的软件包管理器,因此类似于安装 CocoaPods。接下来,您可以从 Caffe、Keras 或者其他工具当中获取模型,然后将其转换为 Core ML 模型,并将模型保存下来。在 Apple 的文档中,他们已经告诉你了哪些格式可以转换,但是最受欢迎的模型无疑就是 Keras 和 Caffe 了。
Keras
我将简要介绍一下如何使用 Keras 来进行自定义模型的制作,这样您就可以立刻开始鼓捣机器学习了,也不会觉得自定义模型是无法实现的。Keras 是一个用于开发和评估深度学习模型的 Python 库。如果您打算创建一个用例更为具体详细的模型的话,那么 Keras 正是您所需要的。
例如,如果您想使用 Apple 所提供的某个模型,它可能能够区分自行车和汽车,但是它却无法区分不同类型的自行车:固定把自行车、公路自行车、山地自行车、甚至是概念自行车等等。在这种情况下,您需要拥有自己的数据集,并使用这些自行车类型对图像进行标记,然后创建自己的模型。Keras 由高效的数值计算库提供支持,它本质上是一个能够创建模型的引擎。
支持 Keras 模型的常见引擎还包括了 TensorFlow 和 Theano。我在一些业余项目中使用了 TensorFlow,因为它的文档非常丰富,Google 在支持方面做得非常好。
但是……Python?🐍😑
我已经体验过 Python 的魅力所在了,我认为,学习 Python 或者其他新语言的基础知识,可以开阔您的眼界,对整个编程界能够有更深入的了解。您可以重点关注新语言与您正在使用的语言(例如 Swift)的相似之处,这是一个非常好的方法,同时您也可以看到这门新语言提供了哪些与 Swift 所不同的特性。
在学习关于编程语言理论的过程中,这种做法是一种很好的练习,并且还可以找到哪些是实用的用例。Python 对于初学者而言是非常友好的。很多大学都使用 Python 作为所教授的第一门语言,比如说麻省理工学院、斯坦福大学以及很多在线公开课,所以这是一门很常用的语言,可以应用在许多机器学习工具上。如果您对 Python 不熟悉的话,那么我建议您去学习 Udacity 的相关课程,因为它非常地简单,并且无需经历很多无聊的编程练习,您通常会在很多语言介绍课程中看到这一类的练习。
要配置 Python 环境的话,有一个非常简单的方法,那就是使用 Anaconda。Anaconda 是一个开源的数据科学平台,可以用来管理 Python 的包、依赖关系和环境,这样您就无需自己操心。您可以将其下载下来,然后决定是使用 Python 2.7 还是 3.6。Python 3.0 以上的版本和 Python 3.0 以下的版本之间有非常大的差异,因此无论您决定使用何种版本,只需要选择相应的版本即可。
Keras 模型
Keras 模型由一组模型层 (layer) 所定义,就像之前对神经网络的大概描述一样。您可以在代码中创建这些模型层。我们这里将要创建一个序列模型,然后逐次添加模型层,直到我们对网络拓扑满意为止。首先我们要做的是确保输入的数字是正确的,因为我们在本次讲演中不会涉及到太多的细节,如果您对此好奇的话,可以查看此教程:使用 Keras 和 Python 构建您的第一个神经网络。
我们将简要地介绍几点步骤,以便您能够完成神经网络的创建。与 iOS 应用代码库相比,这里所涉及的代码部分非常少:
- 加载数据。
- 使用序列模型层 (sequential layer) 来定义模型。
- 比较模型。
- 适配模型,这意味着需要运行某些数据来训练模型。
- 评估模型——借助训练完的模型来运行一组数据,查看实际输出与预期输出是否匹配。
万事大吉——只需要用 31 行代码就可以完成神经网络的建立,所以这个步骤是非常平易近人的。一旦您得到了这个自定义模型,那么您就可以使用 Apple 开发的 Core ML 工具包,它将为您生成一个 ML 模型,这样就可以在应用中使用了。
测试与 Instrument
我认为对您的应用进行充分测试是一个明智之举,然后再使用 Instrument 来调试应用。考虑到与应用的其余资源相比,这些模型的占用资源可能会非常大,您应该使用 Instrument 来确保不会引起大量的内存波动 (memory spike) 或者任何可能会对用户体验产生负面影响的因素。在使用机器学习库的时候,这一点是非常重要的,因为机器学习是一个非常新颖的玩意儿,而且通常占用的内存要多得多。
机器学习的未来
一年以来,我一直在关注这个领域,并且也关注其他的社区,例如 Android 以及开发者社区。我们认为以后会发生什么呢?Apple 将会继续大力推广机器学习,我们已经在 WWDC 2017 中看到这一趋势了并且在过去的几年里,他们聘请了很多机器学习专家,最终新的功能也会纳入到开发者工具以及我们开发的应用当中。看看开发者是如何利用这些新 API,这将会非常有趣,因为这可能会让很多应用极大地改善用户体验,并且为使用机器学习来改善应用这个领域开辟出一条新路。
我希望在机器学习资源方面未来能够有所改善。如果我们正视机器学习领域的话,2009 年麻省理工学院认为这并不是很实用的东西。从那时候起,在这过去的十年以来,机器学习得到了很大的发展,但是如今资源的数量才开始大幅上涨。我不建议大家从线性代数教科书开始看,因为这并不必要,并且还很有可能吓到你。我希望能够有更多适合 iOS 开发者的资源。
我认为这些资源将会来自于 Apple 和社区。Apple 在几个月前宣布将自行制作 GPU,所以我认为这样才真正能给设备所提供的功能带来帮助,包括移动设备、笔记本电脑以及其他 Apple 的产品。我认为他们可能会在设备上添加优化过的机器学习芯片。这一点在其他社区中都有所谈论,我关注了很多频道,大家都认为这种做法是自然而然的,这样做更容易让机器学习不会带来负面的性能效果。
其他资源
这将是一个飞速发展的领域,所以如果您有兴趣的话,可以关注一些博客、新闻以及频道,我实际上建立了一个名为 Let’s Infer 的新闻频道。在 WWDC 结束之后,我将会在上面发布新闻,随后我也会建立一个与之相关的频道。
机器学习新闻:
- This Week in Machine Learning and AI
- Keras Blog
- machinethink.net/blog
- alexsosn.github.io/ml/2015/11/05/iOS-ML.html
课程:
- Udacity’s Intro to Machine Learning:如何使用 Python,完全免费!
- Udacity’s Intro to Data Science Nanodegree
- Coursera’s Machine Learning at Stanford
我同时也在制作一个使用了机器学习功能的自行车应用,这就是为什么这里我使用了自行车相关的示例。这个应用将帮助用户弄清楚他们想购买什么类型的自行车,因为第一次购买的用户通常并没有详细的词汇来描述他的需求。例如,他需要一个带有固定把和钢框架的固定式齿轮自行车。应用将会给用户提供建议,然后就可以在应用中在线购买。
问答时间到
听众:我有一个问题,如果将机器学习应用在音乐领域呢,特别是检测节拍或者节奏方面,有没有什么常见的算法或者公式呢,对此您是否有任何建议?我大学毕业的时候,就信号分析领域而言,在这方面有用的技术只有快速傅里叶转换之类的东西。机器学习中有没有与之等价的技术呢?
Meghan:这绝对是机器学习的最佳示例之一,虽然我并没有在 SoundCloud 的机器学习团队中,但是他们的所有图书角我都会看,他们提到了类似的话题,包括如何在 SoundCloud 中使用相关的技术,所以那里有很多相关的文章。我记得我们 SoundCloud 博客当中也有一些相关的文章,Spotify 当中也有很多关于如何构建音乐推荐引擎的文章。其中很大一部分都是借助特定向量 (vector) 或者标签来对歌曲进行标记,然后为用户选择所需的标签。所以或许您会将这首歌打上这几个标签:90 年代、HipHop,然后就是作曲者,并且还有其他各种各样的标签,从而可以划定这个音乐处于何种范围。在我的新闻中,我想我可以放上一篇有关的文章。文章中将更为详细地谈论这一点,并且我知道 Apple 也提供了某种音乐标签配置方案。这对于机器学习而言,的确是一个非常好的示例。
听众:您说,训练以及创建模型会耗费大量的时间和金钱,我想。那么您是否意味着,您的那个自行车示例的训练同样也耗费了极大的精力么?
Meghan:这得看情况了。这取决于您要用机器学习做什么,如果您决定要使用这么多的标签来标注数据,那么这会使您的数据集变得很大,并且需要提供大量的图像,那么您拥有的标签越多、所使用的图像越多,那么模型的训练就越来越昂贵。
如果模型过大,那么您就没办法在设备上进行训练了。您就必须要去服务器上执行此项操作,因此您就需要为此支付服务器的费用。如果您想使用机器学习来作为服务提供的话,那么您还必须要在免费试用后付款。
模型的训练可能会很昂贵,由于这只是累积的结果,如果您只是个人开发者的话,那么这些费用的累积就需要考虑。对我的自行车应用而言,我需要的数据集并不是很大。我实际上就可以在设备上、或者我的笔记本电脑上进行训练,这并不需要太长的时间——到目前为止,我只耗费 15 分钟的时间来训练。不过目前模型仍未完成,因此这很可能会有所增长。但是我并不会说模型训练是非常昂贵的,但是我会说这很可能会导致您付出极大的代价,因此您可以选择在本地设备上来做这些操作,从而来节省花费。
听众:我很好奇,如果没办法使用 iOS 11 的话,但是还想使用 MLKit 的话,您有没有什么好的建议呢?
Meghan;如果您没法使用 iOS 11 的话,那么很显然,您就无法使用 Apple 推出的 Core ML 库了,但是在 iOS 11 之前您仍然可以实现机器学习。您可以使用 Metal Performance Shaders 的卷积神经网络、NPSCNN 或者 Accelerate 的基础神经网络子例程 (subroutine)。这些工具并不是很称手,但是它切实可用。
听众:您是否见过在本地训练模型的示例呢?
Meghan:我没有见过。但是我知道这是可行的。Apple 并没有为我们提供这方面的功能,但是我也知道 Apple 在内部曾已经做到了。比如说,在照片应用中,相关的模型训练是在设备上进行的,如果我们最终也可以这样做的话,那么无疑是非常有用的功能。对我们现在而言,这并不是很实用,因为设备的计算力还是很稀缺的,但是我们希望未来计算力会越来越丰富、越来越使用。我知道,现在有很多方法是可以在本地训练模型的。
About the content
This talk was delivered live in June 2017 at AltConf. The video was recorded, produced, and transcribed by Realm, and is published here with the permission of the conference organizers.


